




新浪科技 韩大鹏
编辑 周峰
6月27日晚,北京国贸写字楼2座灯火通明。林晓宇疾步往返于运维部与研发部的走廊上,表情有些凝重。
一场因阿里云故障引发的突发事件,导致他所在的互联网金融公司几近瘫痪。在运维部工作近一年,林晓宇首次受到公司各层级领导的“关注”。
“很多部门的Leader都打电话,问我怎么回事”,面对质疑,林晓宇很是无奈。他回忆说,事发时,业务数据无法读取,交易短暂停滞,客服投诉量激增……运维部和开发部启动了自检,因服务器无法登录及文件存储NAS不能服务,问题也被很快确认:阿里云出了问题。
不能坐以待毙!
林晓宇所在的运维部启动了应急预案:在线服务失效,转为本地服务的Kubernetes容器集群,结果失效。采取手动更改,对象存储OSS失效,SLS失效……
留给他的,只有等待。
在等待的过程中,林晓宇一直琢磨:宣传时说“提供99.9%可靠性”,难道我们就是那0.1%?
惊魂一小时
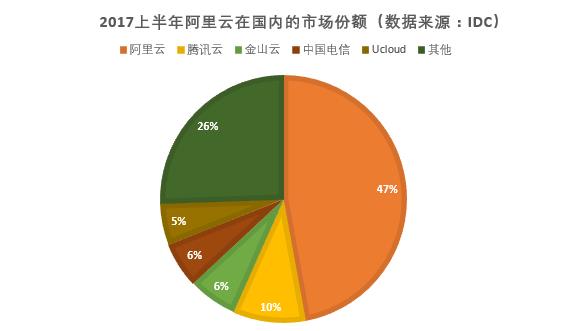
根据阿里云官方描述,其在中国公共云市场占有率超过2至5名的总和,目前中国有40%的网站都在阿里云上运营,一半独角兽公司也在使用阿里云。以这个体量计算,即便是那0.1%的用户,因为不明原因“宕机”所产生的焦虑感,也足以在社交网络上掀起轩然大波。
当天下午4点半开始,不断有“阿里云宕机”的消息在微博和微信群中传出。用户们指出,故障原因集中表现在官方网站和控制台无法访问。而当时,阿里云内部人员向新浪科技提供的第一份回应是账户登陆异常,云服务器不受影响,此次故障并非宕机。
但官方回应迅速发酵出第二轮不满情绪。大量用户在新浪科技发出的微博下面投诉其他功能也被波及——和林晓宇一样,除了无法登陆之外,OpenSearch失效,ONS失效,NAS失效,OSS失效——简单来说,除了登陆环节异常外,阿里云的多个产品在该时段均无法使用。
最终,阿里云在下午发布故障公告,确认了除部分管控功能外,MQ、NAS、OSS等产品的部分功能出现访问异常。此次事故从16点21分至17点30分,时长约一小时。
一位用户点评道:中国互联网半壁江山,惊魂整整一小时!
半壁江山还是0.1%?
郭宁显然在另外半壁江山里。27日晚高峰,他走出望京的写字楼,挤上地铁,打开手机刷了眼新闻,才知道这天下午阿里云“挂”了。
“什么异常都没有。”郭宁目前在一家IT公司负责开发团队,产品均托管在阿里云上,涉及ESC和其他多个云服务。但他向新浪科技表示,自己的产品没有受到任何影响。“网上那些问题一个都没碰到。”
实际上,不只是郭宁,新浪科技接触到的多名开发人员中,大多数都和郭宁一样,在宕机期间内毫无感觉。而唱吧、e代驾等使用阿里云的移动互联网应用,也几乎没有发出过抱怨的声音。
不过,对于那些“惊喜”一小时的用户来说,麻烦是切切实实的存在。据新浪科技不完全统计,此次事故受影响的范围十分广泛,包括电商、互金、通讯语音及教育行业等。阿里云客服人员表示,“此次属于大面积故障,基本上平台大部分业务全挂了”,但具体影响范围及用户数量无法确定。
更麻烦的还在后面。
林晓宇说,虽然故障后来得到了排除,但部门需要进行业务数据修复,这无疑增加了工作量。
一家从事电商业务的员工告诉新浪科技,当天正进行用户拉新活动,注册短信接口全部失效,导致新增量在一两小时内为零,“老板不会关心服务器异常,他只会认为是我们工作没做到位”。
一个bug引发的惨案
次日凌晨,阿里云发布了故障原因说明:工程师团队在上线一个自动化运维新功能中,执行了一项变更验证操作。这一功能在测试环境验证中并未发生问题,上线到自动化运维系统后,触发了一个未知代码bug,错误代码禁用了部分内部IP,导致部分产品访问链路不通。后续人工介入后,工程师团队快速定位问题进行了恢复。
新浪科技曾向阿里云方面询问具体的bug触发原因,但对方拒绝回答。
各种段子一般的推测加入了下一轮传播。其中流传最广的一个版本是:刚刚招了两个实习生——误删了登陆服务。
“实习生误删登陆服务之说,应该是不存在的。”IT领域自媒体“Linux高薪集训营“引用了原美团点评运维架构师及马哥教育联合创始人张sir的解读,“一方面,大型互联网公司尤其是阿里云这样的公司,对工程师权限有着极为严格的控制,因为阿里云数十万台服务器,支撑了全国各行各业千亿以上规模的线上业务,不可能让实习生不熟悉的情况下,给予过高的管理权限。这是极其不专业的做法。”
张Sir从阿里巴巴内部得知,这次故障影响了整个阿里巴巴集团,其中包括阿里云、蚂蚁金服、天猫、飞猪、优酷等事业群,其中阿里云的故障等级为S1。
 故障影响有多严重
故障影响有多严重在阿里巴巴的线上业务故障级别中,对S1的定义是:核心业务重要功能不可用,影响部分用户,造成一定损失。
“故障的严重程度是非常高的,整个阿里集团的核心业务,以及依托阿里云的公司,很多都受到了影响。”张Sir表示。
不过,新浪科技发现,天猫、支付宝、飞猪、优酷等相关产品的访问当天并未受到影响。
至于具体原因,是一个核心应用请求虚拟IP地址(Virtual IP Address VIP)列表的时候得到了空列表,导致几千个VIP不可用,进而影响到了整个集团的业务。
“VIP是集群业务的入口,通过一个VIP的地址,可以实现一组业务的访问。如果数千个VIP被禁用了,可能后端上万台的服务、应用、数据库等将直接无法访问。”张Sir解释。这也符合阿里云的官方解释:“本次故障测试通过了,在生产环境触发了一个未知bug。”
对此,阿里云方面不予置评。
“鸡蛋不能放在一个篮子里”
实际上,云服务宕机波及大量互联网应用并不罕见。去年2月28日,云计算鼻祖亚马逊AWS的云存储团队在调试时错输了一条指令,意外移除了大量服务器,导致进出AWS东一服务区基础设施的流量瞬间消失,停机长达3小时之久。
由于AWS在美国市场处于领先地位,包括Adobe、Airbnb、Github、纳斯达克、Netflix、Slack、通用电气、Quora等知名科技公司均被殃及。根据外媒估算,此次宕机造成了最高数千万美元的损失。
“鸡蛋不能放在同一个篮子里,就是这个道理。” 中国平安运维部负责人在接受新浪科技采访时指出,云服务是把“双刃剑”,一方面,的确为众多企业、尤其是中小企业带来了便利,但在发生问题时,给企业带来的影响和损失也是巨大的。
该负责人称,因行业不同,影响及损失有所区分。例如电商企业,一旦发生云计算事故,直接影响到销售额,同时供应商的利益可能会受到牵连,还有潜在的企业诚信等问题。
从用户层面看,因为故障会导致即时信息无法获取,降低体验感。而对于那些以网络进行交易的用户来说,损失将更大。
同样是去年,纳斯达克的报价传输系统发送的测试数据在7月份被第三方机构不当使用,出现重大错误。谷歌、苹果、亚马逊一度出现不合理的股价暴跌,其中亚马逊暴跌了87%。而在2013年,纳斯达克就出现过类似错误,并导致当天停盘长达三小时。
“很多大企业都会分散选择云服务商”,该负责人表示,一般情况下,小型企业受限于资金或人员等因素,可能会将所有服务放在同一品牌的云服务上。而多数中型企业,会选择多个厂商同时服务。但是,不同厂商间的产品属性存在差异化,可能会导致数据无法同步等情况出现。
信誉如何用赔偿解决?
几年前,阿里云曾推出100倍故障赔偿,即由于阿里云故障导致产品无法正常使用的情况,阿里云将提供100倍的故障时间赔偿。
但阿里云相关负责人向新浪科技表示,赔偿问题将按照相关服务保障条款进行处理。
“必须要有详细的清单”,客服人员表示,根据业务损失情况,法务部人员和业务专员会进行核查,核查无误会进行赔偿。
新浪科技查询了阿里云的产品及服务协议规定,按照目前的规定,包月服务和资源包服务发生故障,赔偿总额不会超过服务器内故障涉及服务费用的总额。如果时按量付费,赔偿总额不会超过过去12个月,故障涉及服务的已缴纳费用总额。
但对于那些经历了宕机痛苦的阿里云用户们来说,赔偿与否已经不是当下最重要的问题了。曾经,阿里云因为“靠谱”被广大网友呼吁站出来帮铁总解决12306订票难的问题,但此刻,林晓宇不由地开始怀疑阿里云是否真正可靠。
 云计算故障编年史
云计算故障编年史
“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)





![[吃瓜]](https://n.sinaimg.cn/commnet/2018new_chigua_org.png "[吃瓜]") 机房故障在所难免就像突然停电一样。只要不是经常出问题和问题不能及时得到解决都可以理解!@阿里云客户满意中心
机房故障在所难免就像突然停电一样。只要不是经常出问题和问题不能及时得到解决都可以理解!@阿里云客户满意中心 












