




雷锋网 AI 科技评论报道: DeepMind 悄悄放出了一篇新论文,介绍了一个「AlphaZero」。一开始我们差点以为 DeepMind 也学会炒冷饭了,毕竟「从零开始学习」的 AlphaGo Zero 论文 10 月就发出来、大家已经讨论了许多遍了。可定睛一看,这次的 AlphaZero 不是以前那个只会下围棋的人工智能了,它是通用的,国际象棋、日本象棋也会下,所以去掉了名字里表示围棋的「Go」;不仅如此,围棋还下得比上次的 AlphaGo Zero 还要好——柯洁在得知 AlphaGo Zero 之后已经感叹道人类是多余的了,这次一众围棋选手可以牵着国际象棋选手们再痛哭一次了。
从技术的角度讲,一个通用的强化学习模型还比之前的已经足够简单的专用于下围棋的模型表现更好?「没有免费的午餐」定律难道失效了?

AlphaGo 的一路进化中,我们见证了 DeepMind 的工程师们对深度强化学习本质的思考和尝试,也看到了不断的优化中带来的无需先验知识、降低资源消耗、提高训练速度等等可喜的技术进步。从使用人工特征、出山之战全胜打败樊麾、发出第一篇论文的 AlphaGo Fan,到 4:1 击败李世石、运行在 50 块 TPU 上、纪录片已经上映的 AlphaGo Lee,再到乌镇 3:0 击败柯洁、只用 4 块 TPU 就打碎了人类所有击败 AlphaGo 幻想的 AlphaGo Master 之后,我们又等来了抛弃人工特征、抛弃所有人类高手棋局,全靠自学成材继续超越 AlphaGo Master 的 AlphaGo Zero。在我们觉得 AlphaGo Zero 已经成为尽善尽美的围棋之神的时候,DeepMind 出人意料地带来了这个更通用的、能下各种棋类的、而且在围棋中的表现更上一层楼的通用强化学习模型,「AlphaZero」。
过往几个版本的 AlphaGo Zero 大家想必都比较熟悉了,不过我们还是简单回顾一下,方便和新的 AlphaZero 对比。AlphaGo 中一直都有深度有限的蒙特卡罗树搜索(MCTS),然后主要靠策略网络和价值网络分别预测下一步落子的点以及评估当前的局势。在更早版本的 AlphaGo 中,策略网络和价值网络是两个不同的深度神经网络,Zero 版本中是同一个 ResNet 的两组输出;AlphaGo Zero 之前几个版本中都需要先把局面转换为高一层的人工特征再作为网络的输入、需要先学习人类棋谱再转变到自我对弈的强化学习、有一个单独的快速走子网络进行随机模拟,AlphaGo Zero 则把局面落子情况直接作为网络的输入、由随机的网络权值直接开始强化学习、舍弃快速走子网络直接用主要的神经网络模拟走子。可以看到,AlphaGo Zero 的思路和模型结构都得到了大幅度简化,带来的是更快的训练和运行速度,以及更高的棋力。而这样简单的模型就能带来这样好的结果,也是让研究者们对 AlphaGo Zero 发出惊叹的原因。
如何从围棋到更多其实一直以来人们在编写下棋的 AI 的过程中,都会针对每一种棋的不同特点设计一些专门的技巧在其中。AlphaGo Zero 中实现策略和价值两个网络的带有残差的 CNN 网络其实刚好就利用到了围棋的一些特点:比赛规则是平移不变的,这和卷积神经网络的共享权值相吻合;棋子的气和卷积网络的局部结构相吻合;整张棋盘是旋转、对称不变的,在训练中可以方便地运用现有的数据增强和组合方法;动作空间简单,只需要在一个位置落单一类别的棋子;结果空间简单,要么是赢,要么是输,没有平局。以上种种特点都可以帮助 AlphaGo Zero 顺利、快速地训练。
现在 DeepMind 的研究人员们想要把 AlphaGo Zero 变成更通用化、能下更多不同棋的算法时候,就需要重新思考其中的一些处理方法。比如国际象棋和日本象棋中,如何走子高度取决于当前的子所在的位置,而每个子又有各自不同的走法;棋盘的局势是不可旋转、不可镜像的,这会影响行棋的方向;象棋可以有平局;日本象棋中甚至可以把捕获的对手的棋子重新放到棋盘上来。相比围棋,这些特点都让计算过程变得更复杂、更不适合 AlphaGo Zero 这样的 CNN 网络。相比之下,2016 年世界象棋算法锦标赛(TCEC)的冠军 Stockfish 就是一个使用人类高手的手工特征、精细调节过的权重、alpha-beta 剪枝算法、加上大规模启发式搜索和不少专门的国际象棋适配的程序。最近刚刚击败了人类日本围棋冠军的最强算法 Elmo 也是差不多的情况。
AlphaZero 是 AlphaGo Zero 的通用化进化版本,它继续保持了 AlphaGo Zero 中不需要人工特征、利用深度神经网络从零开始进行强化学习、结合蒙特卡洛树搜索的特点,然后更新网络参数,减小网络估计的比赛结果和实际结果之间的误差,同时最大化策略网络输出动作和蒙特卡洛树搜索可能性之间的相似度。
AlphaZero 与 AlphaGo Zero 之间的具体区别有以下几个:
AlphaGo Zero 会预计胜率,然后优化胜率,其中只考虑胜、负两种结果;AlphaZero 会估计比赛结果,然后优化达到预计的结果的概率,其中包含了平局甚至别的一些可能的结果。
由于围棋规则是具有旋转和镜像不变性的,所以专为围棋设计的 AlphaGo Zero 和通用的 AlphaZero 就有不同的实现方法。AlphaGo Zero 训练中会为每个棋局做 8 个对称的增强数据;并且在蒙特卡洛树搜索中,棋局会先经过随机的旋转或者镜像变换之后再交给神经网络评估,这样蒙特卡洛评估就可以在不同的偏向之间得到平均。国际象棋和日本象棋都是不对称的,以上基于对称性的方法就不能用了。所以 AlphaZero 并不增强训练数据,也不会在蒙特卡洛树搜索中变换棋局。
在 AlphaGo Zero 中,自我对局的棋局是由所有之前的迭代过程中出现的表现最好的一个版本生成的。在每一次训练迭代之后,新版本棋手的表现都要跟原先的表现最好的版本做对比;如果新的版本能以超过 55% 的胜率赢过原先版本,那么这个新的版本就会成为新的「表现最好的版本」,然后用它生成新的棋局供后续的迭代优化使用。相比之下,AlphaZero 始终都只有一个持续优化的神经网络,自我对局的棋局也就是由具有最新参数的网络生成的,不再像原来那样等待出现一个「表现最好的版本」之后再评估和迭代。这实际上增大了训练出一个不好的结果的风险。
AlphaGo Zero 中搜索部分的超参数是通过贝叶斯优化得到的。AlphaZero 中直接对所有的棋类使用了同一套超参数,不再对每种不同的棋做单独的调节。唯一的例外在于训练中加在先前版本策略上的噪声的大小,这是为了保证网络有足够的探索能力;噪声的大小根据每种棋类的典型可行动作数目做了成比例的缩放。
AlphaZero 释放威力作者们用同样的算法设定、网络架构和超参数(只有刚刚说到的噪声大小不同),分别训练了下国际象棋、日本象棋、围棋的三个 AlphaZero 实例。训练从随机初始化的参数开始,步数一共是 70 万步,mini-batch 大小 4096;5000 个第一代 TPU 用来生成自我对局,64 个第二代 TPU 用来训练神经网络(雷锋网 AI 科技评论注:第二代 TPU 的存储器带宽更高)。
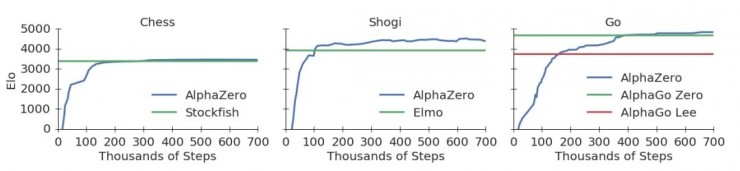
以 Elo 分数为标准,AlphaZero 在完成全部的 70 万步训练之前就分别超过了此前最好的国际象棋、日本象棋和围棋程序 Stockfish、Elmo 和 AlphaGo Zero。如果说在数千个 TPU 的帮助下用 8 小时的训练时间就能超过 AlphaGo Lee 版本还算合理,大约 40 万步训练之后继续以不小的优势胜过 AlphaGo Zero 还是让人吃了一惊的,AlphaZero 中放弃了一些(可能)会带来优势的细节之后,以通用算法的身份击败了已经看起来很完美的专门下围棋的 AlphaGo Zero,「没有免费的午餐」定律仿佛在这里暂时失效了一样。
DeepMind 在论文当然也让完全训练后的 AlphaZero 与 Stockfish、Elmo 和 AlphaGo Zero(训练时间为 3 天)进行了实际的比赛,分别 100 场,每步的思考时间限制为一分钟;AlphaGo Zero 和 AlphaZero 都运行在配备 4 块 TPU 的单个服务器上。

结果并不意外,AlphaZero 在国际象棋中面对 Stockfish 一局未输,日本象棋中共输 8 局,面对 AlphaGo Zero 也拿下了 60% 的胜率。
在 AlphaZero 和各个版本的 AlphaGo 中,我们都知道算法在深度神经网络的帮助下大大减小了蒙特卡洛树搜索的规模。在与 Stockfish 和 Elmo 的对比中,这个提升显得相当明显:AlphaZero 下国际象棋只需要每秒搜索 8 万个位置,Stockfish 的数字是 7 千万;AlphaZero 下日本象棋要每秒搜索 4 万个位置,而 Elmo 的数字是 3 千 5 百万;同时 AlphaZero 还都取得了压倒性的棋力优势。这里的深度神经网络就像人类一样,能有选择地思考更有潜力的下法。论文中还测试了思考时间的效率。以 40ms 思考时间的 Stockfish 和 Elmo 为基准,AlphaZero 的棋力随思考时间增加得更快。DeepMind 的研究人员甚至由此开始质疑以往人们认为下棋任务中 alpha-beta 剪枝算法优于蒙特卡洛树搜索的观念到底是不是正确的。

作者们最后还和人类对比验证了 AlphaZero 学到的国际象棋知识如何。他们从人类在线下棋的棋谱中找了出现次数多于十万次的常见开局形式,发现 AlphaZero 也能独立学到这些开局,而且经常在自我对局中使用。而且,如果比赛是以这些人类常用的开局形式开始的,AlphaZero 也总能打败 Stockfish,这说明 AlphaZero 确实学到了国际象棋中的各种局势变化。
总结在人类把棋类作为人工智能研究的重要关卡以来的几十年间,研究者们开发出的下棋算法几乎总是避免不了人工特征和为具体的棋类做的特定性优化。如今,完全无需人工特征、无需任何人类棋谱、甚至无需任何特定优化的通用强化学习算法 AlphaZero 终于问世,而且只需要几个小时的训练时间就可以超越此前最好的算法甚至人类世界冠军,这是算法和计算资源的胜利,更是人类的顶尖研究成果。DeepMind 愿景中能解决各种问题的通用 AI,看起来也离我们越来越近了。
论文地址:https://arxiv.org/pdf/1712.01815.pdf
雷锋网 AI 科技评论编译。
相关文章:
现场|David Silver原文演讲:揭秘新版AlphaGo算法和训练细节
AlphaGo称王!柯洁输掉三番棋最后一场
AI要完爆人类?解密AlphaGo Zero中的核心技术
李开复、马少平、周志华、田渊栋都是怎么看AlphaGo Zero的?

“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











