
当AM2遇上Conroe 新一代CPU架构技术对比 | ||||
|---|---|---|---|---|
| http://www.sina.com.cn 2006年06月12日 13:12 IT168.com | ||||
|
作者:IT168.COM 【IT168 资讯】5月23日,AMD未能如期发布其最新的Socket AM2接口的处理器,但市场上却已悄然铺货,大量的Socket AM2处理器流入市场。这一次AMD的行动出人意表的低调,与之前K8发布之时的张扬大相径庭。而Intel也计划不久后发布全新的Conroe,那么AM2和Conroe相比较,究竟谁优谁劣呢,接下来从几个方面来讨论这个问题。 制造工艺决定生产成本 道理很简单,从芯片的原料成本来讲,处理器的成本主要取决于CPU核心的大小,在同一个圆晶芯片中,要想切割出更多的处理器核心,其中一个常用的手段就是提升制造工艺水平,减少每个CPU核心的表面积,增加产量的同时更好的去控制生产成本。 在全新推出的Socket AM2接口的处理器中,AMD仍然采用了90nm工艺进行生产。虽然AMD会推出一系列热设计功耗(TDP)仅为65W和35W的AM2处理器(Energy Efficient Processor),相对于原有产品,省电幅度高达54%。但从目前所得到的AM2处理器报价表来看,相同PR值的处理器中,TDP为35W的产品价格要比65W的产品高出接近30美元,这无疑会为低功耗产品的推广带来极大的困难。这种情况在双核处理器中同样存在。 相对于AMD留守于90nm生产工艺,Intel在数年前就已经展开了65nm制造工艺的研究。2003年11月,英特尔就开始使用65nm工艺来制造4Mb静态随机存取存储器(SRAM);而在2005年65nm工艺就已经进入实用阶段。2005年下半年采用65nm工艺的Yonah移动处理器就已经与我们见面,到2006年英特尔在Presler核心上已经全面引入65nm生产工艺,而即将面世的Core核心同样会采用65nm工艺生产。更为先进的生产工艺使Intel得以很好的控制生产成本,同时也可以更好地控制功耗和发热量。就Intel即将推出的Conroe处理器而言,其TDP为65W,比以往采用90nm工艺生产的产品要大为下降,与AMD的AM2平台主流产品相当。如果按性能/瓦特来计算处理器的效能提升了40%,功耗却下降了40%。 另一方面,由于生产成本大为降低,Intel将于Conroe处理器发布的同时对其下产品进行大规模大幅度的降价,把单核心的Pentium 4处理器推向入门级市场,其降价幅度最高超过60%,这对于AMD来说简直就是噩梦!此外Intel还会推出一颗低端的Pentium 4 524处理器(3.06GHz/1MB L2/533MHz FSB),售价为69美金,这与目前AM2最低端的Semoron的售价非常接近。而Pentium 4 524还具备一个更为杀手锏的武器——HyperThreading(超线程技术),虽外频较低,但具备超线程技术的廉价Pentium 4 524,绝对会得到不少消费者的喜爱。 指令执行管线 由于微架够上没有做出太大的改变,AM2处理器的指令执行管线仍然和Socket 939一样,同为17级流水线设计。K8处理器的流水线架构是相当高效的,相比Intel同时代的Prescott核心31级流水线更为优秀,这在939平台得到充分的验证。也许是对其流水线架构的信心,又或者是AM2的推出过于仓促,AMD没有在流水线架构上做出调整,这对于一个全新的平台来说或多或少总会令人失望。 相对于AMD,Intel在新处理器微架构上做出的调整要大刀阔斧得多,流水线架构的调整也最为明显。基于Core核心的Conroe处理器的流水线从Prescott核心的31级缩短为14级,与目前的Pentium M相当。众所周知,流水线越长,频率提升潜力越大,但是一旦分支预测失败或者缓存不中的话,所耽误的延迟时间越长。如果一旦发生分支预测失败或者缓存不中的情况,Prescott核心就会有39个周期的延迟。这要比其他的架构延迟时间多得多。而对于Conroe来说,14级流水线的效率要比Prescott核心的31级要高很多,延时却要低得多。 在缩短流水线级数的同时,Core 微架构前端的改进还包括分支预测单元。分支预测行为发生在取指单元部分。首先,它使用了很多人们已经熟知的预测单元,包括传统的 NetBurst 微架构上的分支目标缓冲区(Branch Target Buffer, BTB)、分支地址计算器(Branch Address Calculator, BAC)和返回地址栈(Return Address Stack,RAS)。然后,它还引入了2个新的预测单元——循环回路探测器(Loop Detector, LD)和间接分支预测器(Indirect Branch Predictor,简称IBP),其中循环回路探测器可以正确预测循环的结束,而间接分支预测器可以基于全局的历史信息做出预测。Core 微架构在分支预测方面不仅可以利用所有这些预测单元,还增加了新的特性:在之前的设计中,分支转移总是会浪费流水线的一个周期;Core 微架构在分支目标预测器和取指单元之间增加了一个队列,在大部分的情况下可以避免这一个周期的浪费。 高效的流水线架构和更优秀的分支预测能力,使Conroe处理器的性能远胜于前代Prescott核心的Pentium D,与AMD的AM2相比也要高出不少。当然这不全是流水线架构改进的功劳,还有一点也相当重要,那就是Conroe的解码单元。 解码单元 由于X86指令集的指令长度、格式与定址模式都相当复杂,为了简化数据通路(Data Path)的设计,从很久以前开始,X86处理器就采用了将X86指令解码成1个或多个长度相同、格式固定、类似RISC指令形式的微指令的设计方法,尤其是涉及存储器访问的 load 及 store 指令。所以,现在的X86处理器的执行单元真正执行的指令是解码后的微指令,而不是X86指令。 与以往的处理器微架构不同,Core架构采用了四组指令编译器,也就是四组解码单元,这与Pentium M处理器有些类似。这个变化可以说是 Core 微架构最大的特色之一。自从 AMD 失败的 K5 设计之后,已经有超过十年的时间,X86处理器的世界再也没有出现过四组解码单元的设计。所谓四组解码单元,就是指能够在单一频率周期内编译四个x86指令。这四组解码单元由三组简单解码单元(Simple Decoder)与一组复杂解码单元(Complex Decoder)组成。 除了在解码单元数量上提升之外,Core 微架构中的解码单元还拥有更多新特性,其中最为重要的一点就是宏指令融合技术(Macro-Op Fusion)。该技术可以把2条相关的X86指令融合为1条微指令。宏指令融合技术带来的效果是非常明显的。在一个传统的X86程序中,每10条指令就有2条指令可以被融合。也就是说,宏指令融合技术的引入可以减少10%的指令数量。而当2条X86指令被融合的时候,4组解码单元在单周期内一共可以解码5条X86指令。被融合的指令在后面的操作中完全是一个整体,这带来几个优势:更大的解码带宽,更少的空间占用,和更低的调度负载。如果 Intel 宣称的“每10条指令可以融合1次”的说法属实,那么宏指令融合技术本身就将带来巨大的性能提升。 Intel 的宏指令融合技术在AMD的K8处理器(包括Socket 939和AM2)上并不存在,不过AMD拥有与微指令融合技术类似的技术。在 Athlon 处理器中,也存在有微指令融合技术。例如,一条 ADD [mem], EAX 指令在真正执行前中始终保持为一条指令。因此,它在缓冲区中也只会占据1个单元的空间。不过,在 Core 微架构中 load 操作和 SSE 操作等也可以被融合,而 K8 处理器则不行,它会把SSE操作解码成2条宏指令。 微指令融合技术的目的就在于减少微指令的数目。处理器内部执行单元的资源有限,如果可以减少微指令的数目,就代表实际执行的X86指令增加了,可以显著提升执行效能。而且,微指令的数目减少还有助于降低处理器功耗,可谓有益无害。 因此而言,Core 微架构要更具有优势。在一般情况下,它每个时钟周期可以解码4条X86指令,加上宏指令融合技术的话则最多可以解码5条X86指令。而 AMD 的 K8 处理器每个时钟周期只能解码3条。仅当多条复杂指令同时需要复杂解码单元进行解码的时候,K8 处理器的解码单元会胜过 Core 微架构的解码单元。但是考虑到实际程序中的绝大多数X86指令对应简单解码单元的事实,这种情况不大可能发生。 缓存架构对比 上面的表格不仅包括了 Core 微架构和 K8 微架构的存储子系统的特性,还包括了之前的 K7 处理器、Pentium M 处理器及 Pentium 4 处理器等的存储子系统的特性。从表格中我们可以看到各个处理器中存储子系统的详细信息。 通过浏览该表格,很快就可以发现,Core 微架构的存储子系统给人留下非常深刻的印象。它不仅拥有最大容量的二级缓存,而且还拥有较低的缓存访问延迟。共享式二级缓存的设计还可以使单个核心享用完全的4MB缓存。一级缓存和二级缓存的总线位宽都是256-bit,从而可以给核心提供最大的存储带宽。 AM2处理器(K8微架构)拥有64KB的一级指令缓存和64KB的一级数据缓存。不过 K8微架构的一级缓存采用2路组相连结构。相比之下,Core 微架构采用的8路组相连结构的32KB的一级缓存并不会差多少,二者的性能相差不大。而相对于Core 的4MB二级缓存,K8的二级缓存只有1M(高端的双核处理器的二级缓存为1M×2),这使K8处理器的性能受到一定的影响,其带来的负面效应会抵销K8微架构在一级缓存上的优势。单就这两方面而言,AMD在与Intel的对抗中似乎并不处于下风,但再进一步比较,似乎就不是这么回事。
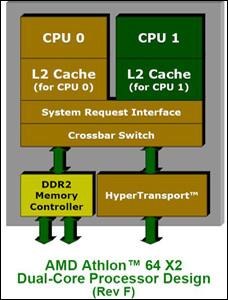
X2的架构示意图 这是AMD的双核处理器X2的架构示意图,从图中看出,X2的两个核心拥有独立的二级缓存,两个核心之间通过“System Request Interface”(系统请求接口,简称SRI)连接,维持二者的协作。SRI单元拥有连接到两个二级缓存的高速总线,如果两个核心的缓存数据需要同步,必须通过SRI单元完成即可。这样的设计使两个核心之间需要不断的通过SRI单元交换信息,消耗系统总线资源。而且这样的设计还存在另一个问题,当一个核心空闲的时候,另一个核心无法使用空闲核心的缓存,造成资源的浪费。
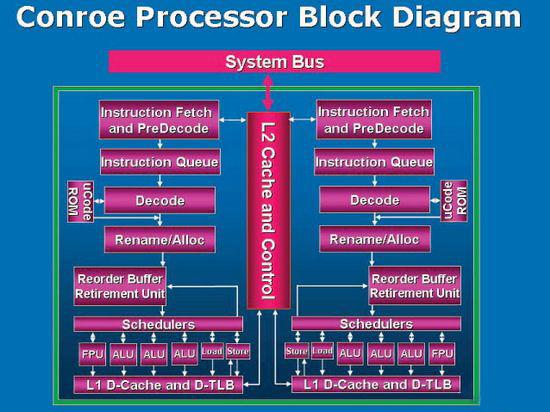
Core微架构 与AMD的独立二级缓存设计不同,Core微架构采用共享二级缓存设计,即两个核心共享4MB的二级缓存。采用共享缓存的好处是非常明显的,除了缓存容量容量利用率较佳,也可以减少缓存数据一致性对缓存性能所造成的负面影响。此外,因共享L2缓存之故,两个核心的第一阶缓存可直接对传数据,毋需通过外部的FSB,进而改善性能。此外还有更为重要的一点,当其中一个核心空闲时,另一个核心可已使用全部4MB缓存,大大提高缓存的使用率,有效提高系统性能。 内存控制器 谈到核心微架构的改变,内存控制器的升级无疑是从Socket 939到Socket AM2转换的最为引人注目的一点,也是AMD所津津乐道的一点。内存从DDR过渡到DDR2已经有很长一段时间了,Intel已经顺利完成内存接口的升级,全面转向DDR2平台,但AMD始终坚守着DDR平台不放,直至现在推出AM2平台才实现内存接口的全面升级。 由Socket 939的Athlon 64开始,AMD便开始采用将内存控制器集成于CPU内核当中的设计,这种设计的好处在于,可以缩短CPU与内存之间的数据交换周期,以前都是采用内存控制器集成于北桥芯片组的设计,改成集成于CPU核心当中,这样一来CPU无需通过北桥,直接可以对内存进行访问操作,有效的提高了处理效率。但这样的设计存在的问题就是对内存延时要求很高,内存延时的提高会给系统性能带来很大的影响。目前来说,DDR2内存的延时还无法和DDR内存相比,但随着技术的发展,DDR2内存的延时也在逐步下降,与DDR内存相比差距已经大为缩短。尽管这样,如果AM2搭配低频的DDR2 533内存甚至更低的DDR2 400,内存带宽的提高所带来的系统性能的提升是无法抵销内存延时给系统性能的影响,因此AM2只有搭配DDR2 667和DDR2 800内存是才能体现到系统性能的提升。但一直以来高频DDR2内存的铺货量不多,而且价格较高,直到近期内存厂商改进工艺和提升产能之后才有所改善。而AMD在此时才推出集成DDR2内存控制器的AM2处理器是比较明智的举措。从媒体的测试看来,搭配DDR2 800内存的AM2平台的内存带宽要比目前Intel平台的内存带宽高,主要的原因是AM2处理器内部集成了内存控制器可以有效降低内存访问延时,这样能带来更高的带宽。 相对于AMD的处理器内部集成内存控制器,Intel平台的内存控制器设计在北桥芯片当中,这无疑为处理器访问内存带来更高的延时。不过Intel为了降低这种设计缺陷带来的影响,在Core微架构每个核心分别内建一组指令及二组数据预先撷取器,而共享的L2缓存控制器内建两组、可动态分配至不同的核心的数据预先撷取器,可根据应用程序数据的行为,进行指令与数据的预先撷取动作,让所需要的内存地址数据,尽量存放在缓存之中,减少存取内存的次数,这样的设计有效地提高了系统性能。此外,改进的内存相关性预测技术及预取单元等可以弥补不集成内存控制器带来的损失。 从另一个方面来看Intel的这个选择也许是因为把内存控制器放到芯片组上使得他们可以在不改变处理器设计的情况下支持新类型的内存,这在从DDR过渡到DDR2平台之时就可以清楚看到,用户可以平滑升级,这为多数人所接受。而AMD由于内部集成了内存控制器,要升级内存平台接口必须改变处理器内部的设计,即集成内存控制器需要升级,我们也就看到了现在Socket 939到Socket AM2的全面升级。无疑现在AM2的内存带宽得到了极大提高,甚至比Intel更强,但用户需要升级的话只能更换整个平台,包括处理器、主板和内存,升级带来的系统性能提升似乎并不那么吸引人。 还有一点,就是目前内存厂商已经研发出新一代的DDR3内存,虽然还没到正是生产投放市场的阶段,但DDR3内存的面世应该是指日可待了。AMD在这个时候才推出支持DDR2的AM2平台,虽然可以享受高频DDR2内存带来的好处,但面对即将到来的DDR3,AMD又将做何应对?推出支持DDR3的新接口处理器?还是想当年坚守DDR平台一样守着DDR2?AM2会成为长久的平台,还是成为短命的产物呢?一切只能等AMD自己决定,消费者才能知晓自己是否被抛弃…… 写在最后 相比Intel在Conroe架构上对性能和功耗大刀阔斧的改革,AMD在对待Socket AM2平台上的态度给人多少有些敷衍塞责的感觉。老实说,很多之前在Socket 754/939时代被AMD培养起好感的普通消费者和DIY玩家对这次AMD“换汤不换药”的做法颇有微词,这一点从主板厂商推出支持AM2处理器的nForce4系列主板上可以得到很好的印证。似乎在即将迈入次世代处理器的关键时刻,AMD丧失了当初在业界发布K8,在普及64位处理器上快人一步,锐意进取的积极作风,大家从前面的已发布的部分Socket AM2接口的处理器的列表中可以看出,AM2版K8处理器相对于之前DDR平台的S939版处理器没有丝毫改变,依旧是90nm的制造工艺,一样的主频,一样的二级缓存,甚至一样的PR值设定,唯一有变化的是核心的代号和据说有所降低的最大热设计功耗,这让很多人觉得AMD根本只是在拿原来的处理器来炒冷饭,套了个AM2的“马甲”来告诉你:这是一款“新”产品,如果AMD不及时拿出具有实质性改变的产品,就凭“吃老本”来和Intel新一代的Conroe处理器正面竞争,将面临着非常被动的局面,至于提升市场占有率将纯粹只是纸上谈兵。 |
| ||||||||||||||||||||||||||||||||||||||||||
| 新浪首页 > 科技时代 > 硬件 > 技术趋势专题 > 正文 |
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||


