




原标题:让计算机“拥抱”常识 | 翻译征文 | 雷锋字幕组
本文为雷锋字幕组“触摸世界前沿科技 | 翻译征文 ”活动收录稿件,译者季一帆。
导读:本文就常识推理问题,分别介绍逻辑符号和神经网络方法,最终引出Choi的研究成果COMET(GPT-2语言模型+Atomic知识库),希望能引起读者的思考。
去年10月的一个晚上,人工智能研究员Gary Marcus在他的iPhone上玩得不亦乐乎,因为他发现最先进的神经网络也不过如此。引起Marcus关注的便是当时名声大噪的GPT-2,该框架的神奇之处在于,只根据一两句提示,就能自主完成一篇流畅合理的英文文章。《卫报》的记者输入一些英国脱欧的标题词汇后, GPT-2写出了一段完整的新闻稿,政治观点、地理信息等应有尽有,令人信服。
Marcus——人工智能炒作的批评者,他对GPT-2做了这样一个小测试,输入:
What happens when you stack kindling and logs in a fireplace and then drop some matches is that you typically start a …(当你把火种和木头堆在壁炉里,然后点燃火柴后,会…)
显然答案是“fire”,GPT-2这样能够完成新闻稿的智能系统应该很容易做出回答,然而,GPT-2的回应却是“ick”。在另一次尝试中,它建议把火柴扔在壁炉里的木头上,这样就能启动一个“irc channel full of people”。
Marcus并不感到惊讶。常识推理(使用常识对世界进行推理的能力,例如“火柴”加“木头”可以得到“火”)数十年来始终是AI研究人员难以跨越的鸿沟。Marcus将他的测试发了Tweet,并评论道:“ LMAO”(网络俚语,指嘲笑性的笑声)。不可置否,神经网络也许是异常强大的语言模拟,但它显然缺乏基本常识。
数分钟后,Yejin Choi(华盛顿大学和艾伦人工智能研究所的计算机科学家)刷到了Marcus的Tweet。时机很尴尬,Choi将在几十分钟后在著名的AI会议上介绍她的最新研究项目COMET,巧合的是,这个系统旨在使用早期版本的GPT-2执行常识推理。
在演讲中,Choi对COMET进行了同样的测试(形式略有修改使其匹配COMET的输入格式):
Gary stacks kindling and logs and drops some matches.
COMET产生了10个关于Gary为什么要放入火柴的推论,虽然并非所有回答都有意义,但前两个回答确实是:“wanted to start a fire”,“fire”。Choi在推文回复了Marcus,然后大步走上领奖台。她说:“看起来COMET表现还不错。”

通向常识的两条路
常识被称为“人工智能的暗物质”——无比重要却令人难以捉摸。这是因为常识是由隐性信息组成的,即人类无意识的用来理解世界的一系列不成文假设和经验法则。例如以下场景:
A man went to a restaurant. He ordered a steak. He left a big tip.(一个男人到一家餐馆,点了一份牛排,留了一大笔小费。)
如果问你这个男人吃了什么,你会毫不犹豫地回答“牛排”。但你仔细想一下,在上面这句话中,没有一处明确指出这个人实际吃了什么。当德州大学奥斯汀分校人工智能实验室主任Ray Mooney在给我做了同样的随机测验后指出这一点时,我其实是有些怀疑的。他说:“人们甚至没有意识到他们正在这样做。“正是常识让我们可以在字里行间顺畅阅读,我们无需被明确告知:在餐馆中,点菜和给小费之间的过程是在进食。
电脑就需要这样。因此不难理解在1958年人工智能领域诞生不久,常识推理就成为人工智能研究的首要问题(“Programs With Common Sense”提出)。自上世纪80年代开始,纽约大学计算机科学家Ernest Davis一直在研究人工智能中的常识,他说:“如果无法理解常识,那么你就无法理解自然语言,也无法处理视觉或规划(In general, you can’t do natural language understanding or vision or planning without it)。”
尽管如此,常识推理研究进展还是慢得出奇。起初,研究人员试图将常识转换为计算机语言:逻辑。他们认为,如果可以写下人类常识的所有不成文规则,计算机就应该能够用它们进行推理,就像做算术一样。这类方法后来被称为“良好的老式人工智能(GOFAI)”。虽然取得一些早期成功,但严重依赖人工定义,使其无法进行扩展。新西兰奥克兰大学的AI研究员Michael Witbrock说:“原则上,以逻辑形式表示知识始终是有限的(The amount of knowledge which can be conveniently represented in the formalisms of logic is kind of limited in principle)。”“事实证明,这是一项异常艰巨的任务(It turned out to be a truly overwhelming task)。”
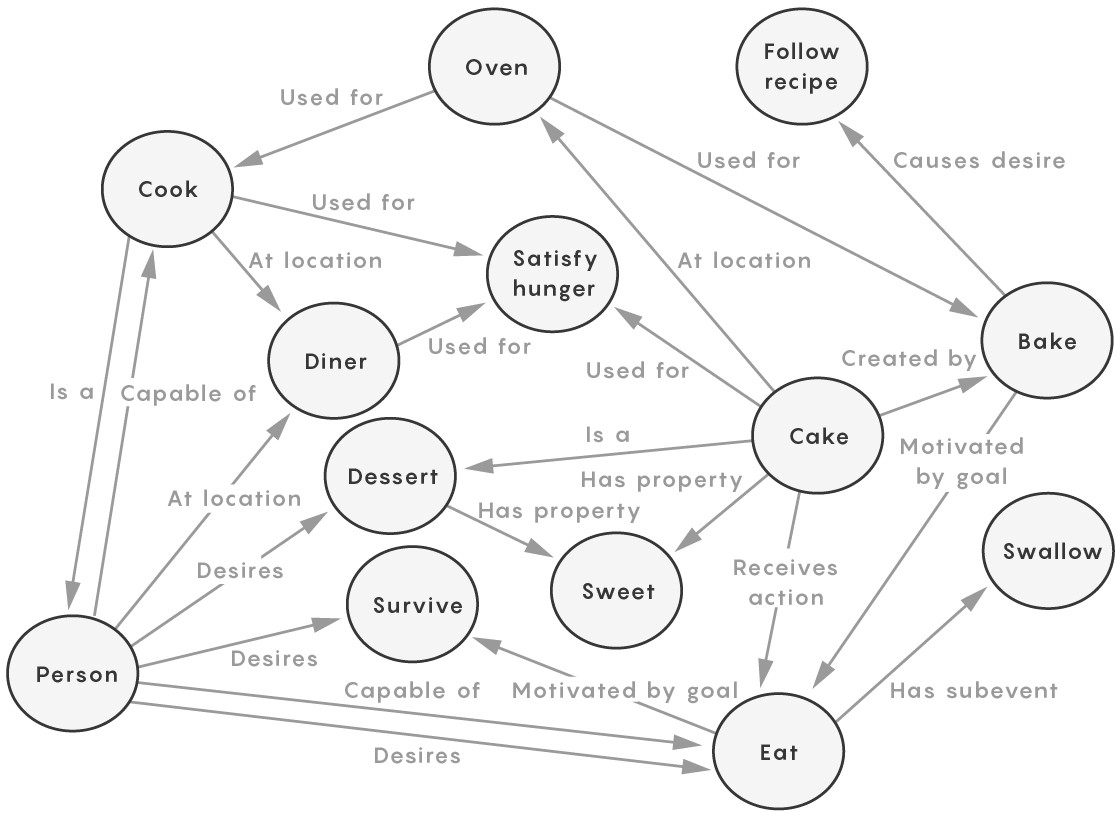
即使是对所有可能的逻辑关系进行简单映射,也会很快遇到麻烦。在上图中一些关系始终成立(吞咽总是饮食的一部分);一些偶尔成立(一个人在餐馆吃饭);一些是不成立的(一个人不可能吃还在烤箱里的蛋糕)。而像“cook”这样的节点,既可以指厨师,也可以指烹饪活动。doi: 10.1109/MIS.2009.72
使用神经网络进行深度学习提供了另一种选择。神经网络通过模拟生物大脑中相互连接的神经元层,在不需要程序员事先指定的情况下自主学习。在过去的十年里,更多的训练数据,更复杂的神经网络,彻底改变了计算机视觉和自然语言处理。但是,尽管神经网络能用于各个领域,且表现出明显的智能——在自动驾驶领域,在国际象棋和围棋中击败最出色的人类玩家——但AI系统始终无法尽如人意,难以实现常识推理使得系统表现愚蠢甚至致命。Davis说:“获得常识,理解常识,用常识进行推理——从来都不容易(Acquiring it, representing it, reasoning with it — it’s all hard)。
现在,Choi 和她的合作者融会贯通,推出COMET(commonsense transformers的缩写)——通过最新的语言建模扩展了GOFAI符号推理,旨在使计算机“理解”书面语言进行深度学习。COMET的工作原理是将常识推理想象为对新输入产生合理响应的过程,而不再是通过查阅庞大的百科全书式数据库进行死板的推论。
Mooney在自己的研究中使用到COMET,她评论道:“COMET试图将两种截然不同的AI方法融合在一起。”帕洛阿尔托研究中心的常识推理和人工智能专家Leora Morgenstern花了几十年时间研究常识推理问题,他认为COMET的思路可以帮助推动这个领域的发展:“Yejin的工作真是让人感到兴奋,这会为常识推理推来一座新的大门(One of the reasons I’m so excited about what Yejin is doing is I think it will inject new life into the common-sense reasoning community)”,“深度学习真的,真的非常强大——继续用它探索常识吧(Deep learning is really, really powerful — let’s figure out how to harness it for common sense)。”

无穷无尽的规则
相比于特定规则与定义,常识才是我们的日常。Witbrock认为,“常识”一词既可以指一种知识,也可以指对这种知识的态度。他说:“我认为(这是)广泛可重用的背景知识,而不是特定的学科领域。一个人应该掌握这些知识。”例如,在餐馆点菜、付钱,意味着人们在这里进食;把火柴扔在一堆木头上意味着有人在试图生火。
大多数常识知识的隐含性使它们很难被明确地表达出来。Morgenstern说:“你两岁或四岁时学到的东西,是没有办法明确写到书上的。”然而,早期的人工智能研究人员认为,虽然困难但也不是完全没有办法。布朗大学的计算机科学家Ellie Pavlick说:“也许我们可以把世界上所有的事实都写下来,大概几百万条就够了。”因此在过去,构建这样一个的知识库是实现自动化常识推理的第一步。
What you learn when you’re two or four years old, you don’t really ever put down in a book. --Leora Morgenstern
但实际上,建立足够大的事实知识库是异常艰难的。1984年,常识推理项目Cyc启动,其目标是对400篇百科全书文章所包含的全部隐性常识进行编码。近30多年来,该项目从未停止。至今,Cyc的知识库——用一种密集的、定制的逻辑符号编码——已包含“数百万个集合和概念以及超过2500万个断言”。然而,Davis和Marcus在2015年发表文章指出,“Cyc对人工智能研究的影响相对较小。”在这之后,又进行了一系列常识,包括为知识库编写条目、通过机器学习挖掘文档,均未能解决常识推理问题。
为什么会这样?Pavlick解释说:“因为不确定因素太多了。比如说,我听到有人说‘下雨了’,那么我可以推断,如果我在外面会被淋湿,但要是用什么东西挡雨的话就不会淋湿了。”其他一些特殊情况就更难预料。Cyc这样的知识库可能包含许多关于某人在餐馆点菜时通常发生的情况,但仍然可能发生一些不常见或是离奇的事情,比如吃霸王餐,比如因一点误会大打出手等等,这些潜在的可能性怎么能被详尽列出呢?”正因此,Choi说:“常识的覆盖范围永无止境,纯粹基于符号知识的方法注定要失败。”
即使能够建立一个比现今知识库大100倍或1000倍的知识库,这个系统仍然存在严重缺陷:所谓的脆弱性问题。因为常识和自然语言一样,从根本上来说都是模糊的。比如当服务员问用餐者,“Are you still working on that?“我们理解他们的意思是”你吃完了吗?”但是,如果服务员向厨师提出同样的问题,那就是另一回事了。那么,在餐馆中说到“work”意味着什么?是“eating”(食客),还是“working”(厨师)?
你看,这就得看情况了。脆弱性问题即是如此:在知识库中定义明确的关系可以实现强大、可靠的推理,但是无论这些符号系统多么丰富,都无法捕捉人类常识性推理中常遇到的歧义和联想。Pavlick说:“只有在符号定义的范围内,系统才会令人满意。”

神经网络方法
Choi喜欢面对挑战,于是她开始研究常识。当她在2018年加入艾伦研究所(Allen Institute)时,她“预感”到,神经网络可以在知识库进展受制的情况下实现新的进步。虽然她还不知道具体怎么做,但她认为不该全然抛弃符号方法。她说:“过去的研究既没有足量的数据,也没有丰富的计算资源,所以在找到正确的路线之前,我会保留自己的判断。”
Choi和她的同事们开始积极建立自己的知识库,Atomic(“atlas of machine commonsense”的缩写)。Choi说:“我想写一本神经网络的教科书,时刻了解最新进展。”“更巧合的是,当我们建立知识库时,GPT-2诞生了。”

就职于艾伦人工智能研究院,Yejin Choi在常识推理中加入了视觉元素。
GPT-2发布于2019年2月。“预训练语言模型”浪潮彻底改变了自然语言处理,这些系统没有整齐规划的语言符号或规则,相反,它们在神经网络这个“黑箱”中用数百万甚至数十亿参数表示语言。这使得预训练语言模型难以解释,但也使它们异常健壮:可以对噪声或不明确的输入生成预测而不会中断。经过微调可执行特定任务(如问答或翻译),看起来,语言模型似乎能够理解文字内容。
预训练语言模型像是一把万能钥匙,Choi看到用神经网络处理常识的可能性。
如果使用常识知识库(如Atomic)对语言模型进行额外的训练,会发生什么?神经网络能否学会用合理的常识推论来填补Atomic空白,就像GPT-2学会了自动生成新闻报道那样?Choi说:“太奇怪了,从来没有人这样试过;也许他们觉得这肯定不会奏效(It’s almost weird that nobody tried this before; It’s almost as if nobody bothered because they were so sure this would never work)。”
当Choi和她的合作者(Antoine Bosselut,Hannah Rashkin,Maarten Sap,Chaitanya Malaviya和Asli Celikyilmaz)用Atomic中的常识编码对语言模型进行微调后,他们创造出COMET。
它融合了符号推理与神经网络,试图同时解决覆盖率和脆弱性问题。 任何人都可以在COMET中输入日常语言, 如果该事件存在于系统的常识知识库中(例如,在餐馆点餐通常意味着进食),那么COMET可以用已知的信息进行简单推理。对于其他方面,神经语言模型也做出最佳推测。
COMET的表现出乎意料。人工评定认为:COMET自主生成的回答(即神经网络的自主推理结果,而不是已存在于知识库中的知识)”有77.5%是合情合理的。相比人类的表现(86%),仅差不到10个百分点。当输入“ PersonX递给PersonY一些药片”时,COMET推出PersonX为PersonY提供帮助;当输入“ PersonX谋杀了PersonY的妻子”时,COMET推测PersonX可能会藏尸灭迹。
目前为止,COMET表现良好,其不全受知识库的限制,可进行推理扩展。那么,对脆弱性问题表现如何呢?去年年底,我在西雅图的实验室采访Choi时,我把我5岁女儿说的话输入给COMET:“Daddy goed to work.”(注意,’goed‘故意拼错)
Choi皱着眉头:“这可不好回答。”但COMET再一次让人惊艳,它推理出:“爸爸”想要“赚钱”、“做完工作”才能“拿到工资”;它认为爸爸“勤奋”、“有动力”和“尽职尽责”;其他人为他“骄傲”和“感激”;但是考虑到该句子是幼儿园小朋友讲的,那么表达的情绪是“很恼火”。哇!我女儿在我去上班而不是陪她玩的时候肯定表达了这种情绪。Choi说:“Cyc没办法这样处理问题,除非有人手动编码‘goed’表示‘go’。”

“梯子和火箭”
Gary Marcus常说这样一句话:“哪怕你能造出最好最高的梯子,但这不意味着你能就此通往月球(Just because you can build a better ladder doesn’t mean you can build a ladder to the moon)”,以此比喻AI的进步。他和其他评论者认为,COMET依然没有摆脱深度学习的基本限制:“统计≠理解”。Marcus在邮件写道:“COMET在猜测句子可能包含的某些参数方面做得不错,但这并不能解决所有问题。”就像梯子,不管有多高,都不可能登上月球;神经网络也是如此,无论语言模型表现多么强大,它并不真正“知道”把点燃的火柴扔到木头上就会起火。
Choi对此表示同意。她承认,COMET依赖训练数据中的统计模式,而不是真正理解概念来产生响应。Choi说:“COMET真的很擅长'统计',这很好,只是我们必须为它提供更多更全面的数据。”
It was like, ‘Let’s write down all the facts about the world. Surely there’s only a couple million of them.’ --Ellie Pavlick
几百万?如果信息量更大该怎样呢?一些研究人员认为,为了让计算机真正理解常识,我们需要利用语言以外的其他信息,例如视觉或知觉。这些更直接的表示可能才是常识的基础,语言不过建立在这些基础之上。
Pavlick说:“如果我生活在一个没有其他人可以交谈的世界,我仍然会有常识,仍然能够理解世界如何运转,并对我看得到和看不到的东西有所了解。”Pavlick目前正在研究如何通过在虚拟现实中与AI系统交互来教授这些系统常识知识。对她来说,COMET是“真正令人振奋的研究,但并不深入。当'apple'不表示水果'苹果'时,它的实际意义并不是文字来表示的,而是其他某种形式。”
Salesforce的高级研究科学家Nazneen Rajani也有类似的想法,但她认为神经语言模型还有更大的潜力。她正在研究语言模型能否学会对物理常识现象的推理,比如,将装有球的罐子倒过来会导致球掉出来。Rajani说:“现实世界真的很复杂,自然语言就像是对世界运作方式的低维映射(The real world is really complicated,But natural language is like a low-dimensional proxy for how the real world works)”。神经网络可以根据文本提示预测下一个单词,但绝不仅限于如此,“他们可以学到更复杂的东西(They can learn more complex stuff)。”
Choi和她的同事们也在研究通过额外的标注视觉场景来增强COMET。她说:“我们从电影或电视节目中收集整理数据,通过这些信息,模型的性能得以进一步的提高。”
相关工作
Machines Beat Humans on a Reading Test. But Do They Understand?
Computers Evolve a New Path Toward Human Intelligence
Artificial Intelligence Will Do What We Ask. That’s a Problem.
我问Choi说,COMET的方法(将更好的神经网络与改进的常识性知识库相结合)是否在本质上仍是在建造登月梯子。她承认,她的梦想是拥有一个无需人工监督就能从知识库中学习的神经网络,就像GPT-2这样通过大量文本进行学习的语言模型。
但正如Winston Churchill戏称:“民主是最糟糕的政府形式,只是所有其他的形式都已经屡次试过了”。Choi认为,尽管COMET还存在缺陷,但却是当前最有希望的方法。也许仅仅依靠神经网络无法到达“月球”,但它们却是唯一能够脱离地面的方法。“没有这些(神经网络),我们哪儿也去不了。单凭知识库只是原地踏步,COMET将我们带到了空中(Without that, we are not going anywhere. With [knowledge bases] alone, we cannot do anything. It’s COMET that can actually fly in the air)。”
本文更新于2020年5月1日,转载自TheAtlantic.com。
原译文链接,来自雷锋字幕组提供的选题。
本文为雷锋字幕组“触摸世界前沿科技 | 翻译征文 ”活动收录稿件
雷锋字幕组是在 AI 研习社社区由 AI 爱好者组成的字幕/图文翻译团队;
团队成员有大数据专家、算法工程师、图像处理工程师、产品经理、产品运营、IT咨询人、在校师生;志愿者们来自IBM、AVL、Adobe、阿里、百度等知名企业,北大、清华、港大、中科院、南卡罗莱纳大学、早稻田大学等海内外高校研究所;
从 2017 年成立以来,我们翻译了不计其数的技术干货博客,大咖访谈、学术演讲,当然了,还有海外知名院校的人工智能经典课程。
你可以在https://www.yanxishe.com/translation和 https://www.yanxishe.com/courseList找到我们所有的翻译成果。
在雷锋字幕组,你不光可以获取最新海外 AI 资讯,还能看到最有价值的 AI 内容,我们是 AI 知识的学习者,更是 AI 知识的传递者;
加雷锋字幕组微信:leiphonefansub
雷锋网(公众号:雷锋网)雷锋网雷锋网
雷锋网原创文章,未经授权禁止转载。详情见转载须知。




“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











