

选自SingularityHub
作者:Edd Gent
机器之心编译
参与:李泽南、王淑婷
IBM 近日提出的全新芯片设计可以通过在数据存储的位置执行计算来加速全连接神经网络的训练。研究人员称,这种「芯片」可以达到 GPU 280 倍的能源效率,并在同样面积上实现 100 倍的算力。该研究的论文已经发表在上周出版的 Nature 期刊上。
用 GPU 运行神经网络的方法近年来已经为人工智能领域带来了惊人的发展,然而两者的组合其实并不完美。IBM 研究人员希望专门为神经网络设计一种新芯片,使前者运行能够更快、更有效。
直到本世纪初,研究人员才发现为电子游戏设计的图形处理单元 ( GPU ) 可以被用作硬件加速器,以运行更大的神经网络。
因为这些芯片可以执行大量并行运算,而无需像传统的 CPU 那样按顺序执行。这对于同时计算数百个神经元的权重来说特别有用,而今的深度学习网络则正是由大量神经元构成的。
虽然 GPU 的引入已经让人工智能领域实现了飞速发展,但这些芯片仍要将处理和存储分开,这意味着在两者之间传递数据需要耗费大量的时间和精力。这促使人们开始研究新的存储技术,这种新技术可以在同一位置存储和处理这些权重数据,从而提高速度和能效。
这种新型存储设备通过调整其电阻水平来以模拟形式存储数据,即以连续规模存储数据,而不是以数字存储器的二进制 1 和 0。而且因为信息存储在存储单元的电导中,所以可以通过简单地让电压通过所有存储单元并让系统通过物理方法来执行计算。
但这些设备中固有的物理缺陷会导致行为的不一致,这意味着目前使用这种方式来训练神经网络实现的分类精确度明显低于使用 GPU 进行计算。
负责该项目的 IBM Research 博士后研究员 Stefano Ambrogio 在此前接受 Singularity Hub 采访时说:「我们可以在一个比 GPU 更快的系统上进行训练,但如果训练操作不够精确,那就没用。目前为止,还没有证据表明使用这些新型设备和使用 GPU 一样精确。」
但随着研究的进展,新技术展现了实力。在上周发表在《自然》杂志上的一篇论文中(Equivalent-accuracy accelerated neural-network training using analogue memory),Ambrogio 和他的同事们描述了如何利用全新的模拟存储器和更传统的电子元件组合来制造一个芯片,该芯片在运行速度更快、能耗更少的情况下与 GPU 的精确度相匹配。
这些新的存储技术难以训练深层神经网络的原因是,这个过程需要对每个神经元的权重进行上下数千次的刺激,直到网络完全对齐。Ambrogio 说,改变这些设备的电阻需要重新配置它们的原子结构,而这个过程每次都不相同。刺激的力度也并不总是完全相同,这导致神经元权重不精确的调节。
研究人员创造了「突触单元」来解决这个问题,每个单元都对应网络中的单个神经元,既有长期记忆,也有短期记忆。每个单元由一对相变存储器 ( PCM ) 单元和三个晶体管和一个电容器的组合构成,相变存储器单元将重量数据存储在其电阻中,电容器将重量数据存储为电荷。
PCM 是一种「非易失性存储器」,意味着即使没有外部电源,它也保留存储的信息,而电容器是「易失性的」,因此只能保持其电荷几毫秒。但电容器没有 PCM 器件的可变性,因此可以快速准确地编程。
当神经网络经过图片训练后可以进行分类任务时,只有电容器权重被更新了。在观察了数千张图片之后,权重会被传输到 PCM 单元以长期存储。
PCM 的可变性意味着权重数据的传递可能仍然会存在错误,但因为单元只是偶尔更新,因此在不增加太多复杂性的情况下系统可以再次检查导率。「如果直接在 PCM 单元上进行训练,就不可行了,」Ambrogio 表示。
为了测试新设备,研究人员在一系列流行的图像识别基准中训练了他们的神经网络,并实现了与谷歌的神经网络框架 TensorFlow 相媲美的精确度。但更重要的是,他们预测最终构建出的芯片可以达到 GPU 280 倍的能源效率,并在同样平方毫米面积上实现 100 倍的算力。
值得注意的是,研究人员目前还没有构建出完整的芯片。在使用 PCM 单元进行测试时,其他硬件组件是由计算机模拟的。Ambrogio 表示研究人员希望在花费大量精力构建完整芯片之前检查方案的可行性。
他们使用了真实的 PCM 设备——因为这方面的模拟不甚可靠,而其他组件的模拟技术已经成熟。研究人员对基于这种设计构建完整芯片非常有信心。
「它目前只能在全连接神经网络上与 GPU 竞争,在这种网络中,每个神经元都连接到前一层的相应神经元上,」Ambrogio 表示。「在实践中,很多神经网络并不是全连接的,或者只有部分层是全连接的。」
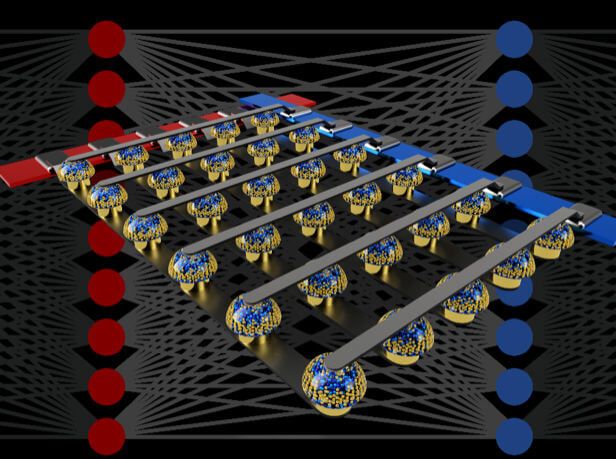
交叉开关非易失性存储器阵列可以通过在数据位置执行计算来加速全连接神经网络的训练。图片来源:IBM Research
Ambrogio 认为最终的芯片会被设计为与 GPU 协同工作的形式,以处理全连接层的计算,同时执行其他任务。他还认为处理全连接层的有效方法可以被扩展到其它更广泛的领域。
这种专用芯片可以让哪些设想成为可能?
Ambrogio 表示主要有两种方向的应用:将 AI 引入个人设备,以及提高数据中心的运行效率。其中后者是科技巨头关注的重点——这些公司的服务器运营成本一直居高不下。
在个人设备中直接实现人工智能可以免去将数据传向云端造成的隐私性顾虑,但 Ambrogio 认为其更具吸引力的优势在于创造个性化的 AI。
「在未来,神经网络应用在你的手机和自动驾驶汽车中也可以持续地学习经验,」他说道。「想象一下:你的电话可以和你交谈,并且可以识别你的声音并进行个性化;或者你的汽车可以根据你的驾驶习惯进行个性化调整。」

“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)










