|
|
|
|
|
SQL Server 2005 �еķ�������������1��http://www.sina.com.cn 2006��09��21�� 19:24 ChinaByte
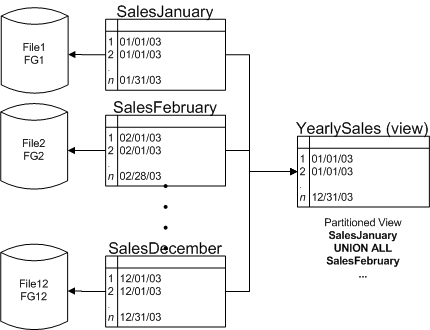
����ΪʲôҪ���з���? ����ʲô�Ƿ���?ΪʲôҪʹ�÷���?�Ļش���:Ϊ�˸��ƴ��ͱ��Լ����и��ַ���ģʽ�ı��Ŀ������ԺͿɹ����ԡ�ͨ������������Ϊ�˴洢ij��ʵ��(����ͻ�������)����Ϣ������ÿ����ֻ����������ʵ������ԡ�һ������Ӧһ��ʵ������������ƺ�����ģ���˲���Ҫ�Ż����ֱ������ܡ��������ԺͿɹ����ԣ��������ڱ���������¡� �������ͱ�����ʲô���ɵ���?���������ݿ� (VLDB) �Ĵ�С������ GB ���㣬������ TB ���㣬��������ﲻһ���ܹ���ӳ���ݿ��и������Ĵ�С���������ݿ���ָ������Ԥ�ڷ�ʽ���е����ݿ⣬�������гɱ���ά���ɱ�����Ԥ��ά��Ҫ���Ԥ��Ҫ������ݿ⡣��ЩҪ��Ҳ�����ڱ�;��������û��Ļ��ά���������������ݵĿ����ԣ��������Ϊ���dz������磬������������½�������ÿ�졢ÿ������ÿ���µ�ά���ڼ�������Сʱ���������ݣ��������Ϊ���۱��dz�����Щ����£������Ե�ͣ��ʱ���ǿ��Խ��ܵģ�����ͨ�����õ���ƺͷ���ʵ�֣�ͨ�����Ա�������̶ȵؼ�����������ķ�������Ȼ���� VLDB �����������ݿ⣬���Է�����˵���˽���Ĵ�С����Ҫ�� �������˴�С֮�⣬�����еIJ�ͬ�м�ӵ�в�ͬ��ʹ��ģʽʱ�����в�ͬ����ģʽ�ı�Ҳ���ܻ�Ӱ�����ܺͿ����ԡ�����ʹ��ģʽ���������ڱ仯(��Ҳ���ǽ��з����ı�Ҫ����)������ʹ��ģʽ�����仯ʱ��ͨ���������Խ�һ�����ƹ��������ܺͿ����ԡ��������۱�Ϊ������ǰ�·ݵ����ݿ����ǿɶ�д�ģ��������·ݵ�����(ͨ��ռ�����ݵĴ�)��ֻ���ġ�������ʹ�÷����仯����������£�����ά���ɱ������ڱ��ж�д���ݵĴ������Ӷ�����쳣�Ӵ������£�����Ӧ�û�������������ܻ��ܵ�Ӱ�졣��Ӧ�أ���Ҳ�����˷������Ŀ����ԺͿ������ԡ� �������⣬����Բ�ͬ�ķ�ʽʹ�ô������ݼ�������Ҫ�����Ծ�̬����ִ��ά������������ܻ���ɴ��۸߰���Ӱ�죬�����������⡢�������⡢����(�ռ䡢ʱ�����Ӫ�ɱ�)�������ܻ�Է�����������������Բ�������Ӱ�졣 �����������Դ���ʲô����?������������÷dz���ʱ���������Խ����ݷ�Ϊ��С�����������IJ��֣��Ӷ��ṩһ���İ����������ص���ܺ���������ں�������У�����������洢�ڶ��������ķ����С��������Ķ��������Ҫ�����Զ��塢���������Microsoft SQL Server 2005 �����������ض�������ʹ��ģʽ��ʹ�ö���ķ�Χ���б��Ա����з�����SQL Server 2005 ��Χ���µı��������ṹ����˼����¹��ܣ�Ϊ�������������ij��ڹ����ṩ�˴�����ѡ� �������⣬������ж�� CPU ��ϵͳ�д���һ�����ͱ�����Ըñ����з�������ͨ�����в�����ø��õ����ܡ�ͨ���Ը��������Ӽ�ִ�ж�����������Ը����ڼ��������ݼ�(������������)��ִ�д��ģ���������ܡ�ͨ�������������ܵ����ӿ��Դ���ǰ�汾�еľۼ����������磬���˾ۼ���һ�����ͱ��⣬SQL Server �����Էֱ�������������Ȼ���������ľۼ�����پۼ��������� SQL Server 2005 �У����Ӵ������ݼ��IJ�ѯ����ͨ������ֱ������;SQL Server 2000 ֧�ֶ��Ӽ����в������Ӳ���������Ҫ��̬�����Ӽ����� SQL Server 2005 �У��ѷ���Ϊ��ͬ����������ͬ������������ر�(�� Order �� OrderDetails ��)����Ϊ�Ѷ��롣���Ż�����������ѷ������Ѷ���ı�������һ��ʱ��SQL Server 2005 �����Ƚ�ͬһ�����е���������������Ȼ���ٽ�����ϲ���������ʹ SQL Server 2005 ���Ը���Ч��ʹ�þ��ж�� CPU �ļ������ ���������ķ�չ��ʷ ���������ĸ���� SQL Server ��˵����İ����ʵ���ϣ��˲�Ʒ��ÿ���汾�ж�����ʵ�ֲ�ͬ��ʽ�ķ��������ǣ�����û��Ϊ�˰����û�������ά�������ܹ���ר�����һЩ���ܣ���˷���һֱ��һ���ܷ����Ĺ��̣�û�еõ���ֵ����á����ң��û��Ϳ�����Ա�Դ˼ܹ��������(���������ݿ���ƱȽϸ���)�����������ŵ㡣���ǣ����ڸ����й��е���Ҫ���ܸ��ƣ�SQL Server 7.0 ��ʼͨ��������ͼʵ�ָ��ַ�����ʽ���Դ����Ľ����ֹ��ܡ����ڣ�SQL Server 2005 Ϊͨ���������Դ������ݼ����з���������������һ���� ������ SQL Server 7.0 ֮ǰ�İ汾�еĶ�����з��� ������ SQL Server 6.5 ����ǰ�İ汾�У�����ֻ��ͨ���������ɣ����������õ��������ݷ��ʱ���Ͳ�ѯ�����С�ͨ�������������Ȼ��ͨ���洢���̡���ͼ��ͻ���Ӧ�ó����������ȷ���ķ��ʣ�ͨ�����Ը���ijЩ���������ܣ�����������������Ƶĸ����ԡ�ÿ���û��Ϳ�����Ա������֪��(����ȷ����)��ȷ�ı���������������ÿ����������ʹ����ͼ������;�������ֽ�����������ܲ�û��̫��ĸ��ơ�ʹ��������ͼ���û���Ӧ�ó������ʱ����ѯ�������������ÿ������������ȷ���������������ݡ����ֻ��Ҫ�������������Ӽ�����ÿ���û��Ϳ�����Ա�������˽����ƣ��Ա�ֻ������Ӧ�ı��� ����SQL Server 7.0 �еķ�����ͼ ������ SQL Server 7.0 ֮ǰ�İ汾�У��ֶ��������������ٵ���ս��Ҫ�������йء�������ͼ���Լ�Ӧ�ó�����ơ��û����ʺͲ�ѯ�ı�д����ȴ���������ܡ����� SQL Server 7.0 �汾�У���ͼ�����Լ����������ѯ�Ż�����Ӳ�ѯ�ƻ���ɾ������صı�(����������)�������������ͼ���ʶ����ʱ���ܼƻ��ɱ��� ������μ�ͼ 1 �е� YearlySales ��ͼ�������Զ���ʮ���������ı�(�� SalesJanuary2003��SalesFebruary2003 ��)��Ȼ����ÿ�����ȵ���ͼ�Լ�ȫ�����ͼ YearlySales�������ǽ������������ݷŵ�һ�����ͱ��С� ����
����ͼ 1:SQL Server 7.0/2000 �еķ�����ͼ ����ʹ�����²�ѯ���� YearlySales ��ͼ���û�ֻ�ᱻ������ SalesJanuary2003 ���� ����SELECT ys.* ����FROM dbo.YearlySales AS ys ����WHERE ys.SalesDate = '20030113' ����ֻҪԼ�����Ų��ҷ�����ͼ�IJ�ѯʹ�� WHERE �Ӿ���ݷ�����(����?������У����Ʋ�ѯ�����SQL Server �ͻ�ֻ���ʱ���Ļ������������ε�Լ����ָ SQL Server �ܹ�ȷ���������ݷ��ϸ�Լ������������Ե�Լ��������Լ��ʱ��Ĭ����Ϊ�Ǵ���Լ�� WITH CHECK�������ý����¶Ա�ִ�мܹ��������Ա����Լ����֤���ݡ������֤�����������������Ч��������Լ��;һ������ܹ������������IJ��롢���º�ɾ�������������������Ӧ�õ�Լ����ͨ��ʹ�ô˹��̴��������ε�Լ����������Ա����ֱ�ӷ���(��������Ҫ֪��)���Ǹ���Ȥ�ı����Ӷ������ʹ����ͼ����Ƶĸ����ԡ�ͨ�������ε�Լ����SQL Server ���Դ�ִ�мƻ���ɾ������Ҫ�ı����Ӷ��������ܡ� ����ע��:Լ������ͨ�����ַ�ʽ��á��������Ρ�;���磬���δָ�� CHECK_CONSTRAINTS ������ִ���������룬����ʹ�� NOCHECK ����Լ�������Լ���������Σ���ѯ��������ת��ɨ�����л���������Ϊ����ȷ��������������Ƿ����λ����ȷ�Ļ������С� ����SQL Server 2000 �еķ�����ͼ �������� SQL Server 7.0 ��������Ʋ������� SELECT �������ܣ����Dz�û��Ϊ�������������κκô���INSERT��UPDATE �� DELETE ���ֻ����Ի�������������ֱ������������ϱ�����ͼ���� SQL Server 2000 �У���������仹���������� SQL Server 7.0 ������ķ�����ͼ���ܡ�����������������ʹ����ͬ�ķ�����ͼ�ṹ����ˣ�SQL Server ����ͨ����ͼ���Ķ�������Ӧ�Ļ�������Ϊ����ȷ���ô����ã���Ҫ�Է��������䴴�����ö��������;���ǣ�����ԭ������ͬ�ģ���Ϊ SELECT ��ѯ���Ķ���ֱ�ӷ�����Ӧ�Ļ��������й��� SQL Server 2000 �н��з��������ơ����á����ú���ѷ�������ϸ��Ϣ����μ� Using Partitions in a Microsoft SQL Server 2000 Data Warehouse�� ����SQL Server 2005 �еķ����� �������� SQL Server 7.0 �� SQL Server 2000 �еĸĽ���������ʹ�÷�����ͼʱ�����ܣ����Dz�û�м������ݼ��Ĺ�������ƻ���ʹ�÷�����ͼʱ�����뵥����������ÿ��������(�����ж�����ͼ�ı�)�����ܼ���Ӧ�ó�����Ʋ�Ϊ�û������˺ô�(�û�������Ҫ֪��ֱ�ӷ����ĸ�������)����������Ҫ�����ı�̫�࣬���ұ���Ϊÿ������������������Լ��������������ø����ӡ���Ϊ������������⣬ͨ��ֻ������Ҫ�浵���������ʱ��ʹ�÷�����ͼ��������������ݱ��ƶ���ֻ�������ֻ������ɾ�������Ĵ��۱��ʮ�ָ߰�����������ʱ�䡢ռ����־�ռ䣬ͨ�����ᵼ��ϵͳ������ �������⣬������ǰ�汾�еķ���������Ҫ������Ա������������������Ȼ��ͨ����ͼ��������������������Ż�������Ҫ��֤��ȷ��ÿ�������ļƻ�(��Ϊ���������ѷ����仯)������һ����SQL Server 2000 �еIJ�ѯ�Ż�ʱ��ͨ�������Ŵ����ķ��������Ӷ�ֱ�������� ������ SQL Server 2005 �У��Ӷ����Ͻ���ÿ��������ӵ����ͬ�����������磬�뿼������һ�ַ���������ǰ�·ݵ����������� (OLTP) ������Ҫ�ƶ���ÿ����ĩ�ķ������С�������(����ֻ����ѯ)�Ǿ���һ��Ⱥ��������������Ⱥ�������ı�;�������� 1 GB ����(���ص��ѽ��������������һ������)��ʹ��ǰ�û�����ϵͳ�������������Ϊ����/���������֧�������/�����������⣬��Ϊÿ����һ�ж���Ҫά���������������Լ��ع��̻����ķѴ�����ʱ�䡣��Ȼ����ͨ�����ַ����ӿ��������ص��ٶȣ�����Щ�������ܻ�ֱ��Ӱ�����������û�����Ϊ���ٶȶ���ʵ�ֲ��������� �����������Щ���ݵ����ŵ�һ���´�����(��)��δ��������(��)�ı��У�������ȼ������ݣ����ڼ�������֮���������� ��֧��Flash
|