|
不支持Flash
|
|
|
|
显卡的能源基地:让你彻底了解显存技术http://www.sina.com.cn 2007年05月15日 09:30 太平洋电脑网
作者:亮仔
显存一直是困扰PC用户的一大难题。当年,为了实现更大的容量,很多人为S3 765显卡艰难地寻找1MB显存模块。随后,尽管我们解决了2D现实的显存容量危机,但是扑面而来的3D时代令显存容量再次捉襟见肘、从纹理压缩到Z轴数据优化,乃至如今通过高速传输通道共享内存,显卡对于显存的疯狂需求逼迫厂商们绞尽脑汁。现在,显存带宽又成了3D速度的拦路虎,无论是提高显存频率还是增加带宽,又或是降低显存延时与功耗,这些都变得非常关键。
一、从GDDR1到GDDR4:显存技术变迁之路 显卡技术的发展简直令人匪夷所思,甚至已经具备基本的PC雏形――GPU类似PC的中央处理器,而显存则几乎等价于内存。毫无疑问,日新月异的GPU对于显存总是如饥似渴。作为显卡厂商,一方面在不断地提高显存频率与显存位宽,但是这毕竟受到制作工艺的限制,不可能无穷尽的拓展。为此,从数据优化技术方面着手成为一种共识,这能够令显存从另一角度来满足GPU的需求。 1.认识显存带宽重要性 从功能上理解,我们可以将显存看作是GPU内核与像素渲染管线之间的桥梁或与仓库。显然,显存的容量决定“仓库”的大小,而显存的带宽决定“桥梁”的宽窄,两者缺一不可,这也就是我们常常说道的“显存容量”与“显存速度”。更快速的显存技术对整体3D性能表现有重大的贡献,数据在渲染管线间传送所花的时间通常比GPU执行功能所花的时间更长,因此提高显存带宽往往能够比提高GPU核心频率取得更为明显的效果。 显存带宽是保证良好性能的基础。以X300SE、GeForce FX5800、GeForce 7300GS等产品为例,就是因为显存带宽上形成的巨大差距而导致性能无法与同时代产品相提并论。那么决定显存带宽的指标优势哪些呢?大家可以抓住显存位宽与显存频率这两个关键因素。显存位宽的计算方法是:单块显存颗粒位宽×显存颗粒总数,而显存频率则是由“1000/显存颗粒纳秒数”来决定。
从GDDR1到GDDR4,显存位宽并不是由芯片技术决定,而取决于板卡设计。但是不同的GDDR显存会在封装成本、频率极限、发热量等方面生产不小的影响,这也导致显存技术在不停地摇摆。时至今日,老迈的GDDR1和GDDR2完全显出疲态,GDDR3彻底取而代之成为绝对的主流,而GDDR4还刚刚浮出水面,仅有少数产品使用。虽说GDDR3和GDDR4并不能决定显存位宽,但是它却决定了显存频率。最终决定性能的因素不仅仅是显存位宽,而是与显存频率同样有关的显存带宽。GDDR3和GDDR4通过实现更高的显存频率来达到极高的带宽。 一般而言,GDDR3显存颗粒的速度在2.5ns以上,通常为2.0ns,此时理论运行频率为1GHz。毫无疑问,如果一款显卡的显存频率只有500MHz,即便其显存位宽达到128bit,其等效显存带宽也仅仅与64bit的1GHz GDDR3显存持平。此外,频率所带来的显存位宽是最为直接的,其执行效率将不会带来任何折扣,也就是说1GHz的64bit GDDR3显存在性能方面要超越500MHz的128bit GDDR显存。 2.GDDR3显存的软肋 GDDR3的缺点在于爆发限制(Burst Limitation),尽管它相对于GDDR2已经有了很大的改善,但是下一代的GDDR4依然大有提升空间。爆发动作是指从内存中连续的地址读取有限的数据,在一个DDR设备的频率周期中,可以读取两个各长n-bit的词元。这两个数据信号必须位在内存中的相同位置(由逻辑电路寻址),稍后才能移往下一位置。
从偶数词元地址起始的全页递增爆发读取(Full-page Increment Burst)来说是没有问题的,因为读取的第二道数据在显存中的地址仍旧和第一道数据相同。但是对由奇数词元地址起始的全页递增爆发读取来说就没有用了,因为两者的数据位置不同,也造成GDDR3设备在预读取功能上的限制。更为令人遗憾的是,GDDR3无法在显存位宽上带来直接的加倍,因此没能也就无法表现出巨大的性能优势。在SDR与GDDR1时代,内外时钟频率是相同的,但在GDDR2内存中,内部时钟变成了外部时钟的一半。以1000MHz的GDDR3为例,数据传输频率为1000MHz,外部时钟频率为1000MHz,内部时钟频率为500MHz。因为内部一次传输的数据就可供外部接口传输4次,虽然以双倍速方式传输,但数据传输频率的基准:外部时钟频率仍要是内部时钟的两倍才行。所以,当预取容量超过接口一次的传输量时,内部时钟必须降低。 此外,GDDR3的显存延时表现也令人无法完全满意。为了解决以往GDDR2的高延时问题,GDDR3采用了改进型的背靠背式读取,但是此时反而让写入延迟增加了,仅仅提高读取延时并不是理想的做法。现在,当GDDR3频率逐步提高时,厂商为了提高稳定性又进一步提高了延时,这对其性能表现也非常不利。
3.GDDR4备受推崇 除了nVIDIA和ATI一直在图形芯片领域激烈竞争,显存竞争也在不断继续着。日前三星更进一步,推出了GDDR4显存芯片,而且具有巨大产量优势的HY与也表示已经为GDDR4作好了一起准备。GDDR4显存具备目前业界最高的显存工作频率,而耗能却很低。同时,配备GDDR4需要的配件更少,约束条件也更低。综合这些优点,nVIDIA与ATI的合作商们准备提前启用GDDR4显存技术,从而彻底解决当前显卡功耗过大、成本过高、显存发热量巨大等棘手的问题。
在设计新的GDDR4显存时,三星采用了一系列尖端技术,包括数据总线转位(DBI,Data Bus Inversion)以及多重前同步码(MP,Multi-Preamble)。这些技术应用到GDDR4的开发中,能有效消除了所有数据的传输延迟。据悉,三星采用了80纳米工艺打造GDDR4显存芯片,首批产品其将工作频率定在2.1GHz。可以说,GDDR4是目前市场上最快速的显存产品了。GDDR4的数据带宽比GDDR3大幅度提升,而耗电却只有70%左右,GDDR4最终将肯定成为高端显卡甚至主流显卡产品的必备显存,无论是nVIDIA还是ATI两家都认同了这一点。 4.GDDR4的成本优势 在传统的GDDR显存的爆发模式中,显存从偶数词元地址开始存取时为爆发递增模式,从奇数词元地址开始时为爆发递减模式。地址数据会做计数动作,所以传递的第二组数据也会和第一组同位置(经逻辑电路寻址后)。当由奇数词元地址开始存取时,会开始反向计数(递减),所以传递的第二组数据,仍旧跟第一组同位置。 从目前发布的GDDR4显存颗粒来看,似乎很轻松地就达到了64Mx64颗粒,也就是说只需4颗显存芯片就能够实现256Bit位宽和256MB容量,这对于节省成本并降低对供电模块的依赖性是很有帮助的。根据HY的技术资料现实,128Mx64将会是下一代GDDR4显存的主流,届时的搭配更更加趋向于256bit位宽和512MB容量,这也符合当前主流3D游戏的应用需求。此外,针对未来高端显卡全面采用384bit的状况下,GDDR4显存也能有更好的支持。最后不可忽视的是,GDDR4在设计上与GDDR3相兼容,因此可以最大限度地降低显卡厂商的转产投资。
二、显存容量与显存压缩 在PC发展的初期,我们对于显卡并没有太高的性能要求,只要做到基本的显示功能即可。通过ISA或者EISA等总线,显卡可以获取需要显示的相关信息数据。不过,这些信息数并未经过处理,因此需要使用显卡的芯片进行加工,这一单元发展到后期就成了GPU。尽管当时显卡处理的数据量并不大,但是缓冲区还是必不可少的,否则连基本的2D显示功能都将无法实现。 显示芯片处理完的资料会全部传送到显存,然后进入极为关键的RAMDAC单元(Digital Analog Converter)。RAMDAC单元所需要完成的任务便是数模转换,因为显卡芯片处理的是数字信息,而普通CRT显示器接收的都是模拟信息,所以这一步是必不可少的。事实上,显卡技术发展初期的焦点并非是显示芯片,也不是RAMDAC,而是像夹心饼干一样的显存。显示芯片与RAMDAC是两个非常忙碌的高速设备,而显存必须随时受它们两个差遣。每一次当显示屏画面改变,显示芯片就必须更改显存里面的资料,而且这一动作是连续进行的。同样的,RAMDAC 也必须不断地读取显存上的资料,以维持画面的刷新。分辨率越高,从芯片传到显存的资料也就越多,而RAMDAC从显存读取资料的速度就要更快才行,为此显存必须在容量以及速度方面达到一定的要求。当3D技术运用之后,数据量可谓呈几何数级上升,此时显存的速度显得更为重要。 1.第一次突破:纹理压缩 自从DirectX 6.0时代开始,渲染出高分辨率下的32位色的3D效果成为众多游戏的追求,而且多边形效果也进入惊人的增长期。毫无疑问,此时所带来的数据量将是惊人的。对于当时的3D游戏而言,如何提纹理效果是一件很头疼的事情,因为与之相配套的3D显卡在性能上无法满足大量纹理的需求,此时使用压缩技术自然是一条捷径。在进入显存之前就进行压缩,这样等于无形中成倍扩大显存容量。
纹理压缩也可以让更多的纹理贴图同时使用,使场景更加丰富多彩。当纹理的容量超出本地帧缓冲区时,压缩省下的空间可以用来增加显示分辨率或用作第三缓冲区。更高分辨率的显示可以使图像看起来更加平滑和细致,第三缓冲区可以大幅度提高性能,因为渲染引擎可以更早开始处理数据而不必等待下一次显示卡的垂直回扫周期。如果要直观地理解,大家可以使用《古墓丽影III》这款游戏,对比第一代《古墓丽影》,纹理压缩压缩技术的确使整体画面效果有了很大幅度的提高。不过以现今的眼光去看,S3TC的纹理压缩比并不高,nVIDIA所采用的光束显存架构以及ATI的3Dc压缩技术已经展现出十分强劲的表现,从而令复杂的纹理也能轻松处理。
2.第二次突破:Z轴数据压缩与清理 对于3D应用而言,纹理填充不仅仅是平面数据,因此Z轴数据压缩技术将是降低显存工作量的关键。为此,各大显卡厂商都开发了相应的技术,其中ATI的HyperZ HD是目前较为先进的一项。Hyper ZD使用的Hierarchical Z技术将用更小的画面像素分块进行计算,这样可以节省更多的像素计算量,而且是在Z轴缓冲里面就进行处理,使得看不见的像素部分不被渲染,大大降低了显存带宽的占用率。最后Hyper ZD将进行Z-Compression & Fast Z Clear操作。Z-Compression的作用就是将像素的Z值进行压缩,使得放入Z轴缓冲里面之后占用的显存带宽更少。在Z-Compression比例上Hyper Z HD有了大幅的提高,8:1的比例已经是上一代一倍。事实上,Hyper ZD技术的精髓在nVIDIA、S3以及XGI显卡中也有体现,只不过具体的算法不完全相同,而且其它厂商没有从市场宣传角度刻意强调。 3.最后的瓶颈:永不放弃的内存资源 非常有趣的是,AGP技术诞生之初并非是为了提高接口带宽,而是利用系统中的内存,因为当时的成本决定显卡很难拥有大容量显存。然而从后续的发展来看,指望AGP调用内存是一种奢望,一代又一代的AGP升级只是将提高带宽作为首要目标。不过随着PCI Express接口的推出,这一局面有望得到改变。 ATI使用Hyper Memory技术,通过PCI Express双向传输的高带宽,这项技术可以共享系统内存来完成显存的作用。事实上,这与当前的整合显卡十分类似,不过Hyper Memory技术因为PCI Express双向传输的原因而获得近似于本地显存的速度,并不会像普通集成显卡那样影响整体速度。更为重要的是,Hyper Memory可以智能分配内存,确保关键的图形数据被保存在速度较快的显存中,这使得数据能够被动态地根据需求存储到显存和系统内存中。
三、回眸AGP之路:PCI Express孕育新希望 当显卡接口由PCI向AGP跃迁之时,厂商最大的期望并非是利用其相对较高的带宽,而是通过这一全新的总线来达到共享内存作为辅助显存的目的。事实上,显存一直是显卡发展的瓶颈之一,不仅显存带宽一直困扰着业界,显存容量也是急待解决的问题。然而随着MRT多渲染目标技术的普及应用,GPU所承担的渲染工作量呈几何数级增加,此时显存带宽都已经捉襟见肘,更不用说最高带宽只有2.1GB/s的AGP 8X通道。在AGP技术发展到4X之后,将内存作为显存辅助这一设计思想就已经付之东流,因为AGP通道所提供的带宽对于显存填充而言仅仅是杯水车薪,其作用仅仅是为GPU与北桥芯片之间建立更为通畅的连接。不过此时的实用价值并不大,毕竟主流显卡的像素填充率并不高,此时并行传输的AGP 8X高带宽仅仅是摆设。为了更好地解决显存数据暂存的问题,新一代显卡在无奈之下不断追求大容量显存,这也直接导致显卡成本居高不下。 小知识:PCI Exrpress开辟显存共享之路 从ISA到PCI,从PCI到历代AGP,总线在不经意间慢慢地升级。每次总线升级总能带来一些新技术与应用,此次的PCI Express也不例外。为了大幅度提高性能,PCI Express摒弃了并行设计,采用了串行传输模式,其中双工状态下的PCI Exrpress提供高达8GB/s的带宽。此外PCI Exrpress内部采用了类似交换机的设计,让各个设备之间可以点对点连接,直接与系统内存控制器连接,也因此为各项显存共享技术提供了应用基础。 1.nVIDIA杀手锏:Turbo Cache开创新时代 PCI Express与Turbo Cache PCI Express已经成为新一代芯片组的标准总线之一,其中北桥芯片目前所提供的PCI Express为x16模式,专门作为图形接口。这种图形接口包括两条专用的通道,一条可由显卡单独到北桥,而另一条则可由北桥单独到显卡,从而提供最高达双向共8GB/s(上行下行均为4GB/s)的峰值带宽。尽管当前部分芯片组还无法实现双工模式,因此造成PCI Exprss x16的带宽减半,但是毫无疑问,如此高的带宽已经肯定足够GPU与北桥芯片沟通使用,甚至略显铺张浪费,因此如何利用带宽就成了关键。 从根本概念来看,包括nVIDIA Turbo Cache在内,我们这里所要为大家介绍的技术都是包含在“将内存作为显存”或者称为“显存映射到内存”的范畴之内,这与当年的AGP纹理调用似乎没有多大的区别。但是请不要忘记,AGP显卡访问系统内存时只能读取其中的纹理,但是却不能把帧缓存分配到系统主内存里,其中帧缓存包括色彩缓存和深度缓存等。如果要在系统内存里分配帧缓存,就必须是固定地从系统内存里分割出来,而不是像大部分AGP显卡所采用的动态分配技术那样。显然,这样很容易造成系统内存的浪费,而且需要到BIOS内手动设定,工作起来十分不便。 需要明确这样一个概念,存储纹理与存储帧缓存是两种完全不同的境界。传统AGP显卡因为受制于带宽以及并行传输模式而无法实现在内存中存储帧缓存,因此这对于整体性能的贡献并不大,让显卡依旧需要依靠大容量显存才能发挥出高性能。然而PCI Express x16总线却截然不同,至少高达4GB/s的带宽以及串行传输模式顺利解决了帧缓存的存储难题。简单而言,AGP模式下的系统内存只能作为具备部分功能的辅助显存,而PCI Express模式下的系统内存可以作为常规显存来使用。
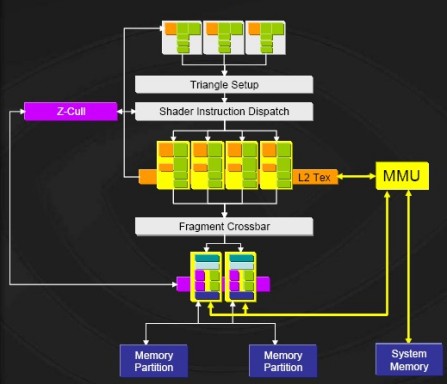
MMU内存管理单元 可以肯定的是,即便使用了Turbo Cache技术,新一代的nVIDIA中低端显卡也不可能完全借用系统内存而彻底抛弃显存,毕竟当前主流内存的频率并不高,特别是在DDR2内存还没有完全普及的时候。毫无疑问,Turbo Cache技术将必须做好显卡本地显存与系统内存之间的调配,这样才能保证发挥出最佳的性能。Turbo Cache技术通过引入MMU存管理单元来实现物理内存的管理。首先我们来看一张传统AGP显卡的3D管线处理流程图,此时所有的数据都进入显存部分,包括Z轴数据缓存。而在Turbo Cache的MMU存管理单元关系下,整个工作流程中多处一个MMU仲裁步骤,它会把本地显存和分配到的系统内存浑然视做一体,GPU在MMU的协作下能智能化地访问系统内存,这意味着除了AGP时代实现的在系统内存存放纹理缓存外,还能把深度缓存、色彩缓存以及渲染对象缓存线性地分布在本地显存和系统内存中,从而显著提高内存的利用率,充分发挥PCI Express的高带宽优势。
此外,内存操作中常见的分配、清场、优化完全由MMU单元来控制实现。更为巧妙的是,MMU完全不处理2D数据,也就是说只要显卡工作在2D模式,那么就没有丝毫系统内存被显卡调用,此时可以充分节约系统内存。以运行PhotoShop等软件为例,3D加速功能没有任何作用,这样更多的系统内存有利于保证性能,而不是浪费在显存中。 Turbo Cache的显存搭配 起初Turbo Cache技术仅仅应用于GeForce 6200TC系列显卡,也是nVIDIA产品线中最低端的PCI Express显卡。GeForce 6200TC系列初步推出两种PCB的公版产品,分别是P282与P262。P282使用mBGA封装的显存,具备较高的速度,可以搭配16MB 32bit显存(一颗显存)或者32MB 64bit显存(两颗显存)。而P262公版采用采用TSOP2封装的显存,可以搭配32MB 32bit显存(两颗显存)或者64MB 64bit显存(四颗显存)。
细心的读者可能已经在担心,为何显存带宽如此之低?联想到市场上64bit显存位宽的产品,其性能表现不禁让人担心。不过大家可能忽略的是,Turbo Cache允许本地显存与系统内存并行工作,也就是说大多数情况下其显存带宽是跌价的。考虑到双通道DDR芯片组已经将内存带宽提高到128bit,因此整体局面将十分可观。唯一有所遗憾的是,本地显存带宽只有32bit的显卡即便搭载Turbo Cache技术也会令2D性能大幅度损失,此时Turbo Cache无法起到任何作用。面对未来的高清晰度视频应用,这将会是Turbo Cache技术的软肋,nVIDIA只有通过在GPU内部集成硬件解码或者补偿技术来解决问题。 2.ATI针锋相对:Hyper Memory不甘示弱 作为nVIDIA最大的竞争对手,ATI自然不会坐视不理,而Hyper Memory便是用来对抗Turbo Cache的绝密武器。ATI选择整合芯片组作为进军芯片组市场的切入点,并且AMD 690G搭载了Hyper Memory技术,被称为是性能最为出色的整合芯片组。在传统意义上,由于整合图形芯片已经集成到北桥芯片内部,因此实现将内存完全作为显存的读写操作十分简单,这与AGP纹理调用有着显而易见的区别。不过ATI的Hyper Memory可谓更进一步,甚至更应该将其理解为独立显卡的范畴。Hyper Memory技术并不需要像nVIDIA的Turbo Cache那样煞费苦心地实现帧缓存存储,因为近水楼台的集成图形核心已经可以很方便地与北桥芯片沟通,此时即便不纯在PCI Express接口的辅助也能轻松实现,只不过带宽降低而已。此外,Hyper Memory技术也实现了灵活的仲裁过程,可以不对2D程序作用,而且能够智能分配内存,不会让大量的系统内存白白浪费。 3.Intel DVMT动态显存技术 目前占据GPU市场份额第一位的并非nVIDIA也不是ATI,而是通过整合芯片组占领市场的Intel。在全新的G965 GMA X3000整合芯片组中,内建的集成图形核心组件除了支持DirectX 9.0c之外,也开始采用DVMT 4.0动态显存技术。GMA X3000与内存间的工作方式相当灵活,与以上介绍的显存共享技术可谓有着异曲同工之妙。显示核心将可以作为显存的系统内存划分为两个部分。一是较小的预分配存储空间,也是GPU的独占空间,操作系统无法使用,其大小可通过BIOS调节,从8MB到32MB。另一部分是通过DVMT划分给GMA X3000的,而其中又有三种DVMT模式。 在Fixed模式中,一段固定大小的内存容量被分配给显示核心。这段将被显示核心独占,大小可由64MB到512MB调节。在DVMT模式中,显卡核心如同其它操作系统那样使用内存,如果一个十分消耗显存的3D游戏开始运行,那么系统自动调用内存分配给显示核心。当GPU不再需要占用这些内存资源时,会自动归还给系统内存。而在 Fixed+DVMT模式中,显示核心本身独占一个64MB的内存空间,而后还有64MB~512MB的动态内存分配空间。 与上述所介绍的显存共享技术相比,Intel G965中所整合的GMA X3000并没有直接可以调用的本地显存,也就是说并不需要诸如Turbo Chache之类的技术。不过好在被作为显存的系统内存通过PCI Express总线与GMA X3000连接,比之以往的AGP 8X有了明显的提高,而且支持双通道内存的Intel芯片组可以提供较高的内存带宽以供X3000图形核心消耗。但是略微遗憾的是,这种方式即便工作在2D模式下也会略微损失性能,占用少量的系统内存还是小问题,被侵占的内存带宽就无法挽回了。虽然综合来看Intel G965所整合的GMA X3000图形核心已经基本摆脱了“鸡肋”的骂名,但是与板载部分显存的集成显卡或者使用显存优化技术的低端独立显卡相比,多少显得有些脆弱。以往在I815E/810E整合芯片组中,Intel曾经尝试板载部分缓存,但是当时仅仅是内存与图形核心之间的缓冲区,并非真正的本地显存,因此短时间指望Intel有很大的技术改进还并不现实。
|