
ДгPentium IIIЕНПлШт SSEжИСюМЏЗЂеЙРњГЬЛиЙЫ | |
|---|---|
| http://www.sina.com.cn 2006Фъ08дТ23Ше 21:21 ЬьМЋyesky | |
|
АЫНфЁЁ
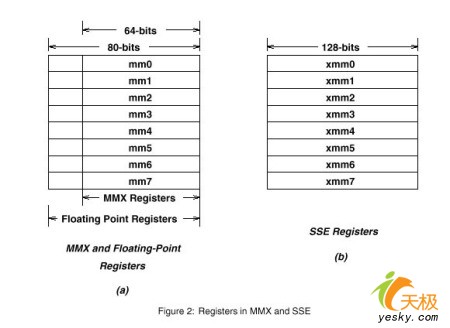
ЧАбдЃК ЁЁЁЁздзюМђЕЅЕФЕчФдПЊЪМЃЌжИСюађСаБуФмШЁЕУдЫЫуЖдЯѓЃЌВЂЖдЫќУЧжДааМЦЫуЁЃЖдДѓЖрЪ§ЕчФдЖјбдЃЌетаЉжИСюЭЌЪБжЛФмжДаавЛДЮМЦЫуЁЃШчашЭъГЩвЛаЉВЂааВйзї(ШчСЂЬхЩљзѓЁЂгвЩљЕРЃЌЛђЯдЪОЦїЕФКьЁЂТЬЁЂРЖЛьКЯ)ЃЌОЭвЊСЌајжДааЖрДЮМЦЫуЁЃДЫРрЕчФдВЩгУЕФЪЧЁАЕЅжИСюЕЅЪ§ОнЁБ(SISD)ДІРэЦїЁЃ ЁЁЁЁШЛЖјЃЌЯжЪЕЪРНчЕФДѓЖрЪ§МЦЫуЖМЛсЭЌSISDФЃаЭГхЭЛЁЃБШШчЖдТѓПЫЗчДЋРДЕФзѓЁЂгвСЂЬхЩљЕРНјааМђЕЅЙ§ТЫДІРэЪБЃЌашНЋжЎЧАЕФМИИіВЩбљжЕРлМгЦ№РДЃЌдйЭЌЕБЧАжЕМгЕНвЛЦ№ЃЌдйГ§вдВЩбљДЮЪ§ЃЌБиаыжиИДМЦЫузѓЁЂгвЩљЕРЁЃПДРДЫЦКѕЦФЮЊМђЕЅЃЌЕЋдкЪЕМЪгІгУжаЃЌУПДЮВЩбљЖМБиаызїЭЌбљЕФМЦЫуЁЃШчОіЖЈЪЙгУCDвєжЪЃЌФЧУДУПУыжжЖМвЊЖдзѓЁЂгвЩљЕРжДаа44100ДЮВЩбљЃЌзмЙВБувЊМЦЫу88200ДЮЁЃ ЁЁЁЁЮЊЛёЕУLeftSumКЭRightSumЕФНсЙћЃЌЗжБ№вЊжДаа6ЬѕжИСюЁЃЫљвдЮЊШЗБЃЛёЕУСЌЙсЕФCDвєжЪЃЌУПУыжгвЊжДааЕФжИСюзмЪ§ЮЊ:44100ДЮВЩбљЁС2ИіЩљЕРЁС6ЬѕжИСюЃН529000ЬѕЃЁЕчФдЯдЪОЕФЕРРэгыДЫЯрЫЦЃЌЕЋЧщПіЛсдуЕУЖрЁЊЯыЯыдк1024ЁС768ЕФЗжБцТЪКЭ24ЮЛецВЪЩЋЯТЃЌМйЖЈУПУыЯдЪО30жЁ(ЫфШЛКУЕЋЗЧЬиБ№ГіЩЋЕФ3DМгЫйадФм)ЃЌНіНіЮЊСЫЗУЮЪУПИіЯёЫиЃЌЖјВЛзіШЮКЮЪЕМЪЙЄзїЃЌУПУыБувЊжДаа70778880ЬѕжИСюЃЌетЯдШЛЪЧИіГСжиЕФИКЕЃЁЃЩшЯывЛЯТЃЌМйШчгаетбљЕФвЛжжДІРэЦїЃЌЫфШЛЫќжЛФмжДааЕЅИіжИСюађСаЃЌЕЋФмНЋФЧаЉжИСюЭЌЪБгІгУгкМИИіЖРСЂЕФЪ§ОнСїЃЌЫйЖШЯдШЛОЭЛсПьЩЯаэЖрЁЃЮвУЧГЦжЎЮЊЁАЕЅжИСюЖрЪ§ОнЁБ(SIMD)ДІРэЦїЁЃЖјЮвУЧЦНГЃЫљЫЕЕФSSE(Streaming SIMD Extensions)БуЪєгкДЫРрЕЅжИСюЖрЪ§ОнЁЃ ЁЁЁЁздSSEЦ№ЃЌЕНФПЧАвбОРњО4ДњЃЌУПвЛДЮИФНјЖМЮЊЮвУЧДјРДЛђЖрЛђЩйЕФОЊЯВЁЃвђДЫНёЬьЮвУЧОЭМђЕЅНщЩмвЛЯТSSEЕФЗЂеЙРњГЬЃЌЯЃЭћФмЖдФудкСЫНтДІРэЦїММЪѕЗЂеЙЪБгаЫљАяжњЁЃ вЛЁЂSSEжИСюМЏ ЁЁЁЁдкСЫНтSSEжЎЧАЃЌЮвУЧЯШЫЕЫЕЖрУНЬхжИСюМЏЕФЗЂеЙЁЃдкSSEЗЂВМжЎЧАЃЌгЂЬиЖћЕФP2жївЊвдMMXЖрУНЬхжИСюМЏЮЊжїЁЃВЛЙ§ЫцзХAMDЗЂВМK6-2ЃЌMMXдчвбОГЩЮЊРњЪЗЃЌШЁДњЫќЕФЪЧЁА3D NOWЃЁЁБКЭSSEЁЃAMDЕБЪБЕФЁА3D NOWЃЁЁБАбЬсЩ§CPUЕФ3DаЇФмзїЮЊвЛИіжївЊвЊЧѓЃЌдкЯрЕБГЬЖШЩЯУжВЙСЫAMDK6аОЦЌИЁЕуДІРэФмСІЩЯЕФВЛзуЃЌЪЙЕУСЎМлЕФЗЧIntelаОЦЌФмЙЛгЕгаГЌЙ§БМЬкЕФ3DадФмЃЌвђДЫK6Ѓ2дкЪаГЁЩЯДѓЛёГЩЙІЃЌЪЙЕУIntelЕФPЂђБИЪмДђЛїЃЌВЂжБНгЕМжТСЫIntelЁАаТШќбяЁБЕФГіС§ЁЃ ЁЁЁЁЁА3D NOWЃЁЁБШчДЫГЩЙІЃЌвджТЫќГЩСЫAMDЕФвЛДѓНОАСЃЌВЂВЛЖЯдкЫќЕФЛљДЁЩЯИФНјМгЧПЃЌвЛжБдкAthlonЩЯЛЙФмМћЕНЫќЕФЩэгАЁЃЮЊДЫЃЌIntelдкPentium IIIжав§ШыИќЯШНјЕФSSEжИСюМЏЁЃ ЁЁЁЁЦфЪЕЃЌдчдкPIIIе§ЪНЭЦГіжЎЧАЃЌIntelЙЋЫООЭдјОЭЈЙ§ИїжжЧўЕРЙЋВМЙ§ЫљЮНЕФKNI(Katmai New Instruction)жИСюМЏЃЌетИіжИСюМЏвВОЭЪЧSSEжИСюМЏЕФЧАЩэЃЌВЂвЛЖШБЛКмЖрДЋУНГЦжЎЮЊMMXжИСюМЏЕФЯТвЛИіАцБОЃЌМДMMX2жИСюМЏЁЃОПЦфБГОАЃЌдРДЁАKNIЁБжИСюМЏЪЧIntelЙЋЫОзюдчЮЊЦфЯТвЛДњаОЦЌУќУћЕФжИСюМЏУћГЦЃЌЖјЫљЮНЕФЁАMMX2ЁБдђЭъШЋЪЧгВМўЦРТлМвУЧКЭУНЬхЦОИаОѕКЭгЁЯѓЖдЁАKNIЁБЕФЦРМлЃЌIntelЙЋЫОЦфЪЕДгЮДе§ЪНЗЂВМЙ§ЙигкMMX2ЕФЯћЯЂЁЃЖјзюжеЭЦГіЕФSSEжИСюМЏвВОЭЪЧЫљЮНЪЄГіЕФЁАЛЅСЊЭјSSEЁБжИСюМЏЁЃ ЁЁЁЁSSEжИСюМЏАќРЈСЫ70ЬѕжИСюЃЌЦфжаАќКЌЬсИп3DЭМаЮдЫЫуаЇТЪЕФ50ЬѕSIMD(ЕЅжИСюЖрЪ§ОнММЪѕ)ИЁЕудЫЫужИСюЁЂ12ЬѕMMX ећЪ§дЫЫудіЧПжИСюЁЂ8ЬѕгХЛЏФкДцжаСЌајЪ§ОнПщДЋЪфжИСюЁЃРэТлЩЯетаЉжИСюЖдФПЧАСїааЕФЭМЯёДІРэЁЂИЁЕудЫЫуЁЂ3DдЫЫуЁЂЪгЦЕДІРэЁЂвєЦЕДІРэЕШжюЖрЖрУНЬхгІгУЦ№ЕНШЋУцЧПЛЏЕФзїгУЁЃSSEжИСюгы3DNow!жИСюБЫДЫЛЅВЛМцШнЃЌЕЋSSEАќКЌСЫ3DNow!ММЪѕЕФОјДѓВПЗжЙІФмЃЌжЛЪЧЪЕЯжЕФЗНЗЈВЛЭЌЁЃSSEМцШнMMXжИСюЃЌЫќПЩвдЭЈЙ§SIMDКЭЕЅЪБжгжмЦкВЂааДІРэЖрИіИЁЕуЪ§ОнРДгааЇЕиЬсИпИЁЕудЫЫуЫйЖШЁЃФЧУДSSEФмЮЊЮвУЧДјРДЪВУДФиЃП ЁЁЁЁгыP2ЪБДњЕФMMXЯрБШЃЌSSEвВЪЧдкдРДЕФДІРэЦїжИСюМЏЕФЛљДЁЩЯЬэМгЕФРЉеЙжИСюМЏЃЌЖМЪЧSIMD(ЕЅжИСюЖрЪ§Он)жИСюЃЌВЛЭЌЕФЪЧЫћУЧДІРэЕФЪ§ОнРраЭВЛЭЌ. MMXжЛФмдкећЪ§ЩЯжЇГжSIMDЃЌЖјSSEжИСюдіМгСЫЕЅОЋЖШИЁЕуЪ§ЕФSIMDжЇГж.MMXПЩвдНјааЭЌЪБЖд2Иі32ЮЛЕФећЪ§ВйзїЃЌЖјSSEПЩвдЭЌЪБЖд4Иі32ЮЛЕФИЁЕуЪ§ВйзїЁЃMMXКЭSSEЕФвЛИіжївЊЕФЧјБ№ЪЧMMXВЂУЛгаЖЈвхаТЕФМФДцЦїЃЌЖјSSEЖЈвхСЫ8ИіШЋаТЕФ128ЮЛМФДцЦїЃЌУПИіМФДцЦїПЩвдЭЌЪБДцЗХ4ИіЕЅОЋЖШИЁЕуЪ§(УПИі32ЮЛГЄ)ЃЌЫћУЧдкМФДцЦїжаХХСаЫГађМћЯТЭМЁЃ
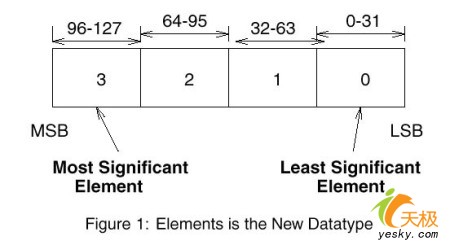
ЁЁЁЁMMXКЭSSEЕФМФДцЦїХХСаМћЯТЭМЃК
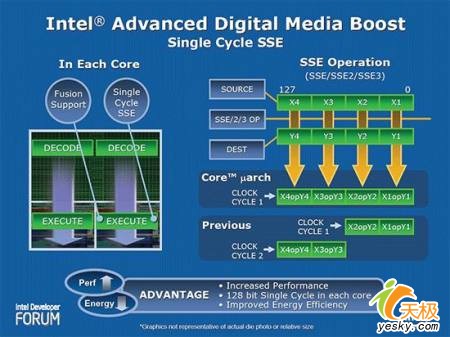
ЁЁЁЁMMXКЭSSEМФДцЦїгавЛИіЙВЭЌЕуЃЌФЧОЭЪЧЖМга8ИіМФДцЦї.MMXЕФМФДцЦїБЛУќУћЮЊmm0ЁЊmm7ЃЌSSEЕФМФДцЦїУћзжЪЧxmm0ЁЊxmm7ЁЃ?Pentium IIIЕФSSEжИСюМЏЪЧЮЊSIMDЩшМЦЕФЃЌЫ§ПЩвдЭЌЪБВйзї4ИіЕЅОЋЖШИЁЕужЕ.вђДЫЃЌРћгУетаЉМгЧПЕФИЁЕуМЦЫуФмСІЃЌЖд3DгІгУГЬађЕФЯИНкБэЯжЪЧгаЪЕжЪадЕФЬсИпЕФЁЃЪТЪЕЩЯЃЌSSEОЭЪЧЮЊ3DгІгУДДНЈЕФ.гЮЯЗКЭЦфЫћЕФЪЙгУКѓЖЫ3DРДЯдЪО2DКЭ2.5DЭМЯѓЕФГЬађЃЌКЭЪЙгУЪИСПЭМаЮЕФгІгУГЬађвЛбљЖМФмЗжЯэЕНетжжКУДІЁЃ ЁЁЁЁЕчФдБэЪОЕФ3DЭМаЮЪЧгУДѓСПЕФБэЪОЭМаЮЖЅЕуЕФИЁЕуЪ§зщГЩЕФЃЌЭЈЙ§ВйзїетаЉЖЅЕуЪ§ОнОЭПЩвдИФБф3DЭМаЮЕФЭтЙл.ЭЈЙ§ЪЙгУSSEжИСюМЏЃЌгІгУГЬађПЩвдЛёЕУИќЖрЕФАяжњЃЌДІРэЦїПЩвддквЛИіЪБжгжмЦкФкДІРэИќЖрЕФЪ§ОнЃЌДѓДѓМгПьСЫ3DЭМаЮЕФЖЅЕуМЦЫуЫйЖШЃЌПЩвдИјгУЛЇДјРДИќЩюПЬЕФ3DЬхбщЁЃЭЌбљЃЌгІгУГЬађПЊЗЂепЛЙПЩвдгУИќЖрЕФЖЅЕуЪ§ОнКЭИќИДдгЕФЫуЗЈРДДДдьГіИќЮЊЩњЖЏЕФ3DЭМЯѓаЇЙћРДЁЃЪЙгУSSEжИСюМЏПЩвдЯджјЕФИФЩЦвЛаЉдк3DВйзїжаОГЃгУЕНЕФМЦЫуЃЌЯёОиеѓГЫЗЈЁЂОиеѓБфЛЛвдМАОиеѓжЎМфЕФМгЁЂМѕЁЂГЫЁЂЯђСПОиеѓЯрГЫЁЂЪИСПЛЏЁЂ ЪИСПЕуЯрГЫКЭЙтееМЦЫуЕШЕШЁЃ
ЁЁЁЁздБМЬкПЊЪМЃЌIntelИїаЭДІРэЦїЕФИЁЕудЫЫуФмСІБуЗЧГЃЧПДѓЃЌгЮЯЗПЊЗЂепМИКѕЖМЧщдИбЁгУИЁЕудЫЫуЁЃгЩгкMMXВЛФмЖдИЁЕуНјааВйзї(ИќдуЕФЪЧЃЌДгMMXЧаЛЛЕНИЁЕуФЃЪНЪБЃЌЛЙЛсдьГЩадФмЕФЫВМфОчНЕ)ЃЌЫљвдMMXВЂВЛФмНЋгЮЯЗЬсЫйжСБШЩшБИЧ§ЖЏГЬађИќИпЕФвЛИіЫЎзМЃЌете§ЪЧMMXСюаэЖрШЫЪЇЭћЕФдвђЁЃМйШчФугУ3DМгЫйПЈзіЭМаЮфжШОЃЌгЮЯЗжаЭъГЩЕФдЫЫу(ФЃФтЁЂ3DБфаЮЁЂееУїЕШ)ЛсКФШЅдМ90%ЕФДІРэЦїЪБМфЁЃвВОЭЪЧЫЕЃЌMMXжЛЮЊДІРэЦїСєГіСЫ10%ЕФЪБМфРДзіЦфЫќЙЄзїЃЌетЛЙЪЧдкФуЪЙгУСЫ3DПЈЕФЧАЬсЯТЁЃ ЁЁЁЁЖјSSEПЩвдгааЇНтОіСЫетИіЮЪЬтЃЌГ§БЃГждгаЕФMMXжИСюЭтЃЌгжаТдіСЫ70ЬѕжИСюЃЌдкМгПьИЁЕудЫЫуЕФЭЌЪБЃЌвВИФЩЦСЫФкДцЕФЪЙгУаЇТЪЃЌЪЙФкДцЫйЖШЯдЕУИќПьвЛаЉЁЃЖдгкгУЛЇРДЫЕЃЌетвтЮЖзХ3DЮяЬхИќЩњЖЏЃЌБэУцИќЙтЛЌЃЌЁАащФтЯжЪЕЁБИќЁАЯжЪЕЁБЁЃАДIntelЕБЪБЕФЫЕЗЈЃЌSSEЖдЯТЪіМИИіСьгђЕФгАЯьЬиБ№УїЯдЃК3DМИКЮдЫЫуМАЖЏЛДІРэЃЛЭМаЮДІРэ(ШчPhotoshop)ЃЛЪгЦЕБрМ/бЙЫѕ/НтбЙ(ШчMPEGКЭDVD)ЃЛгявєЪЖБ№вдМАЩљвєбЙЫѕКЭКЯГЩЁЃ ЁЁЁЁSSEСэвЛДѓгХЕуЪЧПЩвдДѓДѓМѕаЁЪ§ОнМЦЫуЕФжИСюВйзїЪ§ФП.ШчЙћВЛЪЙгУSIMDКЭSSEЃЌвЊНјаавЛИі400ДЮЕФИЁЕуЪ§ГЫЗЈМЦЫуЃЌашвЊбЛЗЪЙгУ400ДЮЕФГЫЗЈжИСюЁЃЖјШчЙћЪЙгУСЫSIMDКЭSSEЃЌдђжЛвЊНјаа100ДЮЕФГЫЗЈжИСюОЭПЩвдЭъГЩЯрЭЌЕФШЮЮёСЫЃЌвђЮЊетРяУПДЮЕФГЫЗЈВйзїЖМПЩвдЭЌЪБЖд4ИіИЁЕуЪ§НјааМЦЫуЁЃ ЁЁЁЁSSEжИСюПЩвдЫЕЪЧНЋIntelЕФMMXКЭAMDЕФ3DNowЃЁММXЯрНсКЯЕФВњЮяЃЌгЩгк3DNow!ЪЙгУЕФЪЧИЁЕуМФДцЗНЪНЃЌвђЖјЮоЗЈНЯКУЕиЭЌВННјаае§ГЃЕФИЁЕудЫЫуЁЃЖјSSEЪЙгУСЫЗжРыЕФжИСюМФДцЦїЃЌДгЖјПЩвдШЋЫйдЫааЃЌБЃжЄСЫгыИЁЕудЫЫуЕФВЂааадЁЃгШЦфЪЧСНепЫљЪЙгУЕФМФДцЦїВювьЦФДѓЉЄ3DNowЃЁЪЧ64ЮЛЃЌЖјSSEЪЧ128ЮЛЁЃЭЌЪБЮЊСЫГфЗжЗЂЛгSSEЕФгХЪЦЃЌIntelв§НјСЫаТЕФЁАДІРэЦїЗжРыФЃЪНЁБвдЬсИпИЁЕудЫЫуЫйЖШЁЃ ДњБэжЎзїЃКPentiumIII
ЖўЁЂSSE2жИСюМЏ ЁЁЁЁSSE2ЪЧIntelЕк2ДњИЁЕуЖрУНЬхДІРэЦїжИСюМЏЃЌЪЧгЂЬиЖћЮЊСЫгІЖдAMDЕФ3Dnow!+жИСюМЏЖјдкSSEЕФЛљДЁЩЯПЊЗЂЕФжИСюМЏЁЃЫќжївЊдіМгСЫ144ЬѕаТНЈжИСюЃЌЪЙЕУЦфДІРэЦїадФмгаДѓЗљЖШЬсИпЁЃ
ЁЁЁЁЙВга144ИіШЋаТЕФжИСюПЩзіШЮКЮЪТЧщЃЌетвВЪЧЕБГѕSSE2ЭЦГіЫљЯыДяГЩжЎФПБъЁЃГЄЖШЮЊ 128-bitбЙЫѕЕФЪ§ОнЃЌдкSSEЪБЃЌИУНіФмвд4ИіЕЅОЋШЗИЁЕужЕЕФаЮЪНРДДІРэЃЛЕЋдкSSE2ЯТЃЌИУЪ§ОнФмбЁгУЯТСаМИжжЪ§ОнБэДяРДДІРэЁЃ ЁЄ4ИіЕЅОЋШЗИЁЕуЪ§(SSE) ЁЄ2ИіЫЋБЖОЋШЗИЁЕуЪ§(SSE2) ЁЄ16ИізжНкЪ§(SSE2) ЁЄ8Иізжзщ(word)Ъ§(SSE2) ЁЄ4ИіЫЋБЖзжзщЪ§(SSE2) ЁЄ2ИіЫФБЖзжзщЪ§(SSE2) ЁЄ1Иі128ЮЛГЄЕФећЪ§(SSE2) ЁЁЁЁгЩгкSSE2ПЩЙЉбЁдёЕФЪ§ОнаЭЬЌКмЖрЃЌЖјЧвЮовЩЕиЯрЕБгагУЁЃ вђДЫЃЌЕБЪБIntel МЋЯЃЭћШэМўПЊЗЂепФмгУSSE2 ЕФЫЋБЖОЋШЗИЁЕужИСюРДШЁДњОЩгаЕФ x86 ИЁЕужИСюЃЌШчДЫвЛРД IntelЫљГЦ Pentium4ЪЧЕБЪБFPU адФмзюЧПЕФДІРэЦїетЯювЅбдЃЌзюКѓвВОЭБфГЩСЫЪТЪЕЁЃдкЯрЙиВтЪджаЃЌSSE2ЖдгкДІРэЦїЕФадФмЕФЬсЩ§ЪЧЪЎЗжУїЯдЕФЃЌЫфШЛдкЭЌЦЕТЪЕФЧщПіЯТЃЌPentium 4КЭадФмВЛШчAthlon XPЃЌЕЋгЩгкAthlon XPВЛжЇГжSSE2ЃЌЫљвдОЙ§SSE2гХЛЏКѓЕФГЬађPentium 4ЕФдЫааЫйЖШвЊУїЯдИпгкAthlon XPЁЃЖјAMDЗНУцвВзЂвтЕНСЫетвЛЧщПіЃЌдкЫцКѓЕФK-8ЯЕСаДІРэЦїжаЃЌЖММгШыSSE2жИСюМЏЁЃ ДњБэжЎзїЃКPentium 4ДІРэЦї
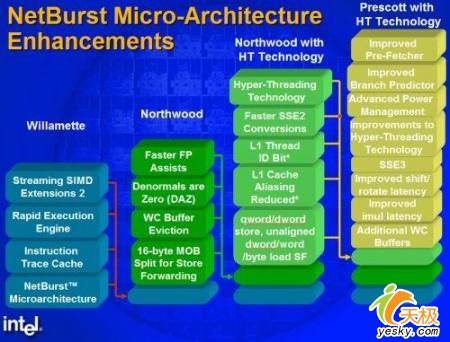
Ш§ЁЂSSE3жИСюМЏ ЁЁЁЁSSE3ЪЧгЂЬиЖћдкбаЗЂPrescottКЫаФЪБЫљв§ШыЕФжИСюМЏЁЃЫќзюЯШБЛГЦЮЊPNI(ЪЧPrescott New InstructionsЕФМђГЦЃЌPrescottаТжИСю)ЃЌЕЋЫќзюжеИФгУСЫвЛИіаТЕФааЯњУћГЦЁЊSSE3ЁЃдкжИСюЕФИДдгГЬЖШЗНУцЃЌЯрЖдгкДЫЧАЕФMMXЁЂSSEЁЂSSE2ЃЌSSE3ЫЦКѕвЊМђНрВЛЩйЁЊДЫЧАMMXАќКЌга57ЬѕУќСюЃЌSSEАќКЌга50ЬѕУќСюЃЌSSE2АќКЌга144ЬѕУќСюЃЌSSE3АќКЌга13ЬѕУќСюЁЃSSE3жИСюМЏет13ЬѕУќСюЙВЗжЮЊ5ИігІгУВуЃК
ЁЁЁЁЕкЖўВужаЕФжИСюЪЧЁАЪ§ОнДІРэУќСюЁБЃЌвЛЙВгаЮхЬѕЃЌЗжБ№ЪЧADDSUBPSЃЌADDSUBPDЃЌMOVSHDUPЃЌMOVSLDUPЃЌMOVDDUPЁЃетаЉжИСюПЩвдМђЛЏИДдгЪ§ОнЕФДІРэЙ§ГЬЃЌгЩгкЮДРДЪ§ОнДІРэСїСПНЋЛсдНРДдНДѓЃЌвђДЫIntelдкетРягІгУЕФжИСюМЏзюЖрЁЂДяЕНСЫЮхЬѕЁЃ ЁЁЁЁЕкШ§ВужаЕФжИСюЪЧЁАЬиЪтДІРэУќСюЁБЃЌвВжЛгавЛЬѕЃКLDDQUЁЃдкетЬѕжИСюжївЊеыЖдЪгЦЕНтТыЃЌгУРДЬсИпДІРэЦїЖдДІРэУНЬхЪ§ОнНсЙћЕФОЋШЗадЁЃ ЁЁЁЁЕкЫФВужаЕФжИСюЪЧЁАгХЛЏУќСюЁБЃЌвЛЙВгаЫФЬѕжИСюЃЌЗжБ№ЪЧHADDPSЃЌHSUBPSЃЌHADDPDЃЌHSUBPDЃЌЫќУЧПЩвдЖдГЬађЦ№ЕНздЖЏгХЛЏЕФзїгУЁЃетаЉжИСюЖдДІРэ3DЭМаЮЯрЕБгагУЁЃ ЁЁЁЁЕкЮхВужаЕФжИСюЪЧЁАГЌЯпГЬадФмдіЧПЁБЃЌвЛЙВгаСНЬѕеыЖдЯпГЬДІРэЕФжИСюЃКMONITORЃЌ MWAITЃЌетгажњгкдіМгIntelГЌЯпГЬЕФДІРэФмСІЁЂДѓДѓМђЛЏСЫГЌЯпГЬЕФЪ§ОнДІРэЙ§ГЬЁЃ ЁЁЁЁДгММЪѕЩЯРДПДЃЌSSE3ЖдгкSEE2ЕФИФНјЗЧГЃгаЯоЃЌвђДЫЫќЮЊPrescottЫљДјРДЕФадФмЬсЩ§ЯрЕБгаЯоЃЌЫќЕФгХЪЦШдЬхЯждкЪгЦЕНтТыЗНУцЁЊIntelаћГЦШчЙћдкЪ§ОнБрТыЫуЗЈЪЙгУLDDQUжИСюЃЌФЧУДгАЯѓбЙЫѕЫйЖШПЩвдЬсЩ§10%зѓгвЁЃдкЕБЪБРДПДЃЌSSE3ШдЪєгкзюЯШНјЕФжИСюМЏЃЌвђДЫAMDЁЂШЋУРДяКѓРДвВдкЫќЕФДІРэЦїжаМгШыЖдSSE3жИСюМЏЕФжЇГжЁЃ ДњБэжЎзїЃКЛљгкPrescottКЫаФЕФPentium 4
ЫФЁЂSSE4жИСюМЏ ЁЁЁЁSSE4жИСюМЏЪЧConroeМмЙЙЫљв§ШыЕФаТжИСюМЏЁЃетЯюдБОМЦЛЎгІгУгкNetBurstЮЂМмЙЙTejasКЫаФДІРэЦїжЎЩЯЕФШЋаТММЪѕвВЫцзХЫќЕФиВелзюжеУЛФмЪЕЯжЃЌетВЛФмВЛЫЕЪЧИівХКЖЃЌЕЋЪЧSSE4жИСюМЏГіЯждкСЫConroeЩЯгжШУЮвУЧПДЕНСЫЯЃЭћЁЃ ЁЁЁЁSSE4жИСюМЏЙВАќРЈ16ЬѕжИСюЃЌВЛЙ§ЫфШЛПлШтДІРэЦїЭЦГівбОгавЛаЉЪБШеЃЌЕЋФПЧАгЂЬиЖћШдУЛгаЙЋВМSSE4жИСюМЏЕФОпЬхзЪСЯЁЃетЯрЕБСюШЫИаЕНФЩУЦЁЃвВаэгЂЬиЖћЪЧЛљгкЬиЪтЕФПМТЧЃЌНіШУЩйЪ§КЯзїШэМўГЇЩЬШЁЕУЪ§ОнЃЌжЛЪЧетжжзїЗЈЪЕдкКмУЛгаЫЕЗўСІОЭЪЧСЫЃЌЬьЕзЯТУЛгаФФМвДІРэЦїГЇЩЬЃЌЯЃЭћздМКаТдіЕФжИСюдНЩйШЫгУдНКУЁЃ ЁЁЁЁВЛЙ§ЃЌДгIntel CoreЮЂМмЙЙеыЖдSSEжИСюЫљзїГіЕФаоИФБЛГЦжЎЮЊЁАIntel Advanced Digital Media BoostЁБММЪѕРДПДЃЌЮДРДSSE4НЋИќзЂжиеыЖдЪгЦЕЗНУцЕФгХЛЏЃЌЮвУЧШЯЮЊSSE4жївЊИФНјжЎДІПЩФмНЋеыЖдгЂЬиЖћЕФClear VideoИпЧхЪгЦЕММЪѕМАUDIНгПкЙцЗЖЬсЙЉЧПгаСІЕФжЇГжЁЃетСНЯюММЪѕЛљгк965аОЦЌзщЃЌIntelЕФЙйЗНАбClear VideoММЪѕЖЈвхЮЊЃКжЇГжИпМЖНтТыЁЂгЕгадЄДІРэКЭдіЧПаЭ3DДІРэФмСІЁЃ
ЁЁЁЁПЩвдЫЕ ConroeЕФЯђСПЕЅдЊвбОШЋУцв§ШыСЫСїЫЎЯпЛЏЕФЩшМЦЁЃЖјжЇГжSSE3ЕФNetBurstЮЂДІРэЦїМмЙЙЫфШЛЬсЙЉ128ЮЛПэжДааЕЅдЊЃЌЕЋНігавЛзщЃЌадФмЪыИпЪыЕЭвЛФПСЫШЛЁЃИќЮЊживЊЕФЪЧЃЌФПЧАвбОгаЯрЕБЖрЕФШэМўеыЖдSSEжИСюМЏНјааСЫгХЛЏЃЌЦфжаАќРЈ2DжЦЭМЁЂ3DжЦЭМЁЂЪгЦЕВЅЗХЁЂвєЦЕВЅЗХЁЂЮФМўбЙЫѕЕШЗНУцЃЌПЩМћЦфгІгУЗЖЮЇЯрЕБЙуЗКЁЃ
ЁЁЁЁХфКЯЭъећЕФ128ЮЛSSEжДааЕЅдЊЃЌвдМАХгДѓЕФжДааЕЅдЊЪ§ФПЃЌConroeДІРэЦїПЩдквЛИіЦЕТЪжмЦкФкЃЌЭЌЪБжДаа128ЮЛГЫЗЈЁЂ128ЮЛМгЗЈЁЂ128ЮЛЪ§ОнМгдигы128ЮЛЪ§ОнЛиДцЃЌЛђзХЪЧ4Иі32ЮЛЕЅБЖИЁЕуОЋШЗЖШГЫЗЈгы4Иі32ЮЛЕЅБЖИЁЕуОЋШЗЖШМгЗЈдЫЫуЃЌетНЋЪЙЦфИќРћгкЖрУНЬхгІгУЁЃвђДЫЃЌSSE4жИСюМЏФмЙЛгааЇДјРДЯЕЭГадФмЩЯЕФЬсЩ§ЃЌетвЛДњдкжкЖрВтЪджадчвбБЛжЄЪЕЁЃЫфШЛЦфВЛЛсЯёЕБФъSSE2жИСюМЏГіЯжЪБФЧбљДјРДОоДѓЕФадФмЬсЩ§ЃЌЕЋЪЧЦфдкФГаЉЬиЪтЗНУцЕФгІгУЛЙЪЧШУЮвУЧЖдЫќГфТњСЫЦкД§ЁЃ ДњБэжЎзїЃКCore 2 DuoДІРэЦї
|
| аТРЫЪзвГ > ПЦММЪБДњ > гВМў > е§ЮФ |
|







| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||



|
ПЦММЪБДњвтМћЗДРЁСєбдАхЁЁЕчЛАЃК010-82628888-5595ЁЁЁЁЁЁЛЖгХњЦРжИе§ аТРЫМђНщ | About Sina | ЙуИцЗўЮё | СЊЯЕЮвУЧ | еаЦИаХЯЂ | ЭјеОТЩЪІ | SINA English | ЛсдБзЂВс | ВњЦЗД№вЩ Copyright © 1996 - 2006 SINA Inc. All Rights Reserved аТРЫЙЋЫОЁЁАцШЈЫљга |