
Core2 Extreme X6800与AMD FX62对比测试(3) |
|---|
| http://www.sina.com.cn 2006年06月19日 10:18 PCPOP-电脑时尚 |
|
Intel Intelligent Power Capability
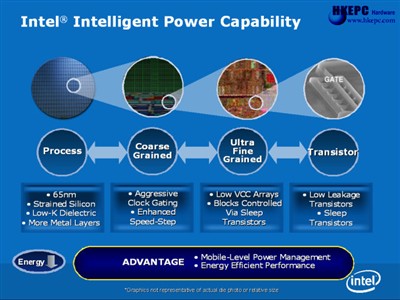 Intel Intelligent Power Capability 由于上代Prescott处理器功耗表现并未如理想,故新一代Core架构针对功耗上作出重良的改善称为Intel Intelligent Power Capability技术,处理器在制程技术作出优化,例如采用先进的65奈米Strained Silicon技术、加入Low-K Dielectric物质及增加金属层,相比上代90奈米制程减少漏电情况达1千倍。但最值得注意的是,Intel加入了细微的逻辑控制机能独立开关各运算单元,只有需要时才会被开启,避免闲置时出现不必要的功耗浪费,称为Sleep Transistors技术,此外,把核心各个Buses及Array采用独立控制其VCC电压,当这些部份被闲置时会被运作于低功耗模式中。
以往要实现达成Power Gating是十分困难,因为在元件开关的过程需要消耗一定程度的能源,而且需要克服由休眠至恢复工作出现的延迟值,故此在Intel Intelligent Power Capability设计考虑到如何优化Sleep Transistor的应用,并确保不会因Sleep Transistors技术而影响效能表现。在Computex TW 06期间,Intel就曾展示一台Core 2 Duo E6300(1.86GHz/2MB L2/1066MHz FSB)在没有采用风扇辅助下完全负载前景播放HD WMV9影片、背景同时不断重覆Lame Audio Encoding WAV to MP3压缩,经过20分钟后仍能保持正常运作,用手触摸处理器散热器表面只是微热,相反北桥散热器的温度要比它还要烫手,很难想像这颗65W TDP的处理器竟有如高水准表现,据Intel表示由于影片压缩工作部份核心元件并不会被使用,会被关掉或是运作于低功耗模式中,纵使其他核心部份正部完全负载。
Intel Advanced Smart Cache
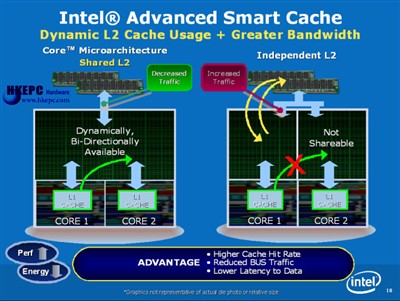 Intel Advanced Smart Cache Intel第一代双核心处理器设计只是单纯地把两颗核心封装在一起,并分享同一个Front Side Bus(FSB)频宽,当其中一颗核心使用FSB时,另一颗便需要等待另一颗的完成才能使用FSB,加上Intel FSB设计是单向存取,还需要透过北桥来读取系统记忆体资料,均严重加重Intel的FSB工作量,两颗核心亦没有直接沟通的桥梁,如果CPU 0的L2 Cache需要读取CPU 1的L2 Cache,更是需要经过FSB及北桥才能达至出现严重的延迟。
Intel Core微架构对此作出了大幅改良,全新的Intel Advanced Smart Cache有效加强多核心架构的效率,传统的双核心设计每个独立的核心都有自己的L2 Cache,但Intel Core微架构则是透过核心内部的Shared Bus Router共用相同的L2 Cache,当CPU 1运算完毕后把结果存在L2 Cache时,CPU 0便可透过Shared Bus Router读取CPU 1放在共用L2 Cache上资料,大幅减低读取上的延迟并减少使用FSB频宽,同时加入L2 & DCU Data Pre-fetchers及Deeper Write output缓冲记忆体,大幅增加了Cache的命中率。
相比现时K8的双核心L2 Cache架构,也是比不上Advanced Smart Cache设计,因为共用L2 Cache能进一步减少了Cache Misses的情况,K8微架构在CPU 0需要读取CPU 1 L2 Cache的资料时,需要向System Request Interface提向要求并透过Crossbar Switch就把取读资料,但CPU 0发现读取自己的L2 Cache没有该笔资料才会要求读取CPU 1的L2 Cache资料,情况等同于CPU 0的L3 Cache,而共用的L2 Cache设计却没有以上需要,AMD已明确在下一代K8L微架构中加入相似Shared Cache技术,但K8L产品在AMD Roadmap中暂定于2007年H2才能登场。
Smart Cache架构还有很多不同的好处,例如当两颗核心工作量不平均时,如果独立L2 Cache的双核心架构有机会出现其中一颗核心工作量过少,L2 Cache没有被有效地应用,但另一颗核心的L2 Cache却因工作量过重,L2 Cache容量没法应付而需要传取系统记忆体,值得注意的是它并无法借用另一颗核心的L2 Cache空间,但SmartCache因L2 Cache是共用的而没有这个问题。
Shared Bus Router除了更有效处理L2 Cache读取外,还会为双核心使用FSB传输进行排程,新加入的Bandwidth Adaptation机制改善了双核心共用FSB时的效率,减少不必要的延迟,其实这个Shared Bus Router设计确实有点像K8的System Request Interface及Crossbar Switch的用途。此外,Intel Advanced SmartCache架构用在行动处理器上亦很有优势,系统工作量不高或是处于闲置状态下,Intel Core微架构可以把其中一颗核心关掉,以减少处理器的功耗,不过却可以保持4MB L2 Cache运是保持工作,而且Shared Bus Router更可以因应L2 Cache的需求量改变L2 Cache的大小,在不必要时关掉部份L2 Cache以减低功耗,但在独立L2 Cache的双核心,如果要把其中一个Cache关掉,则必需要把其中一颗核心的L2 Cache资料移交出来,而且Cache亦会和核心同时被关闭,并没法因应需求实时改变或关掉部份L2 Cache的容量以减低功耗。
Intel Smart Memory Access
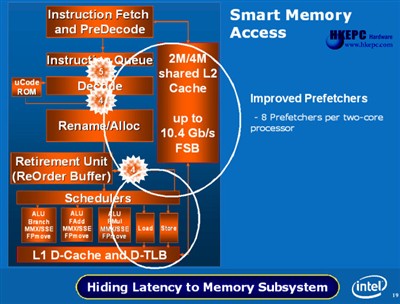 Intel Smart Memory Access Intel Core微架构同时亦改良了记忆体传取效能,每颗核心均拥有3个独立Prefetchers(2 Data and & 1 Instruction),及2个L2 Prefetchers,能同时地侦出Multiple Streaming及Strided Acess Patterns,让核心需要的资料提早准备就绪于L1之中,两组L2 Prefetchers则会分析L2 Cache资料并保留有日后需要的资料于L2 Cache之中。Core微架构的L1 Cache设计放弃使用上代Netburst的Trace Cache设计,因为Trace Cache的最大优点在于较长的Pipeline Stage微架构,而Core只拥有14 Stages故此它改用Banias架构的8-Way 32KB Instruction Cache + 32KB Data Cache设计,虽然容量比AMD K8的 64K Instruction Cache + 64KB Data Cache少一半,但由于AMD的L1 Cache只是2-Way设计,因此Intel的L1 Cache命中率相比K8有较轻微的优势。L2 Cache方面拥有特大的16-Way 256Bit 4MB容量,但Latechy却下降至和AMD K8相约的12-14ns之间,相比AMD K8只有16-Way 128Bit 1MB(部份型号只有512KB),Intel Core微架构在改良Cache系统后拥有绝对优势。
但如果对比系统记忆体存取表现,AMD K8却因内建记忆体控制器而比Intel Core微架构优胜,但由于Core微架构的采用上短Pipeline Stage架构及时脉相对Netburst微架构低,加上高容量的L2 Cache并内建Shared Router Bus减少FSB使用,因此系统记忆体控取的表现差距,已不像与上代Netburst微架构产品般严重,而为了进一步拉近与K8架构上的记忆体效能距离,Intel在Core微架构中加入全新的记忆体读取技术称为Memory Disambiguation。
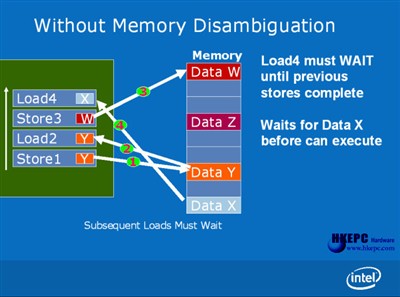 without Memory Disambiguation Memory Disambiguation是一个十分聪明的设计,透过Out of Order过程把记忆体读取次序作出分析。在传统的微架构里,记忆体读取是按排程顺序而被执行,如图上例子Load 4是独立的Data X读取执行,亦必需要等待其他Store 1、Load 2及Store 3工作完毕,纵使Load 4的Data X和前面的资料存取动作并无关系,因为处理器并不会得悉前面的动作会否改变Data X的数值,所以不能重新排序并分析Load 4能否提前执行。
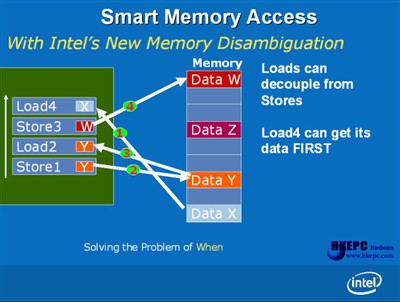 smart memory access 在Intel Core微架构中透过智能的分析机制,能预知Load 4的Data X是完全独立,并可让它提早执行。正因如此Memory Disambigutaion能减少处理器的等候时间减少闲置,同时减低记忆体读取的延迟值,而且它可以侦出冲突并重新读取正确的资料及重新执行指令,保证运作结果不会出现严重,但在正常情况下Memory Disambirutation出错的机会率甚低。
|
不支持Flash
| 新浪首页 > 科技时代 > 硬件 > 正文 |
|
|
|
| |||||||||||||||||||||||||||||||||||||



|
科技时代意见反馈留言板 电话:010-82628888-5595 欢迎批评指正 新浪简介 | About Sina | 广告服务 | 联系我们 | 招聘信息 | 网站律师 | SINA English | 会员注册 | 产品答疑 Copyright © 1996 - 2006 SINA Inc. All Rights Reserved 新浪公司 版权所有 |