
碰撞FX60 英特尔绝密武器Conroe首发评测(3) | |
|---|---|
| http://www.sina.com.cn 2006年05月11日 14:00 太平洋电脑网 | |
|
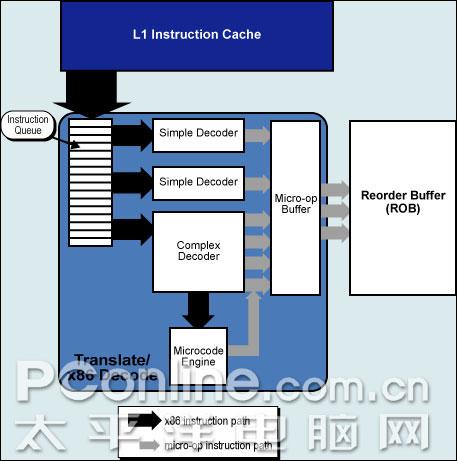
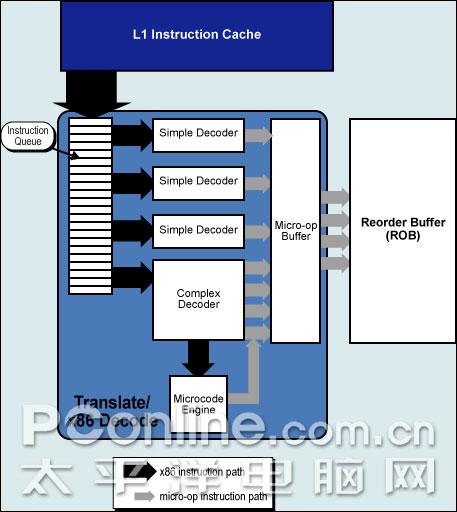
3、Core的内部线程 Core的流水线 INTEL还不能透露Core具体的流水线详情,目前我们只能告知Core采用14条流水线-这和 PowerPC 970是一样的,而之前的Pentium 4 Prescott拥有30条,P6构架为12条。短的流水线意味着Core在频率上的提升只能是缓慢的,而不能够像Pentium 4那样急速上升。 也可以这样猜想,其实Core的流水线设计和P6构架中的流水线是一模一样的,额外多出来的2条流水线完全是为了预留下CPU频率提升的空间而已。2条新的流水线各自成为Core流水线的入口和出口,成为了宏指令融合(Macro-Fusion)、微指令融合(Micro-Ops Fusion)等整合技术的输送站。 Core的内部出口 Core的ROB重排序缓冲区( Reorder Buffer)和RS预留缓存(Reservation Station)要比过去的Pentium M大了接近一倍,而事实上还必须考虑到新的宏指令融合(Macro-Fusion)、微指令融合(Micro-ops Fusion)等高效率的融合技术,这样以来,Core的内部转接速度至少要比Pentium M提高了3倍以上。 Core的处理前站-指令解码
Core的内部线程 这样的P6构架共有3个编译器每周期能执行6条Uops微指令,传送到MB微指令缓冲区,然后MB微指令缓冲区每次再传送3条微指令到ROB重排序缓冲区。
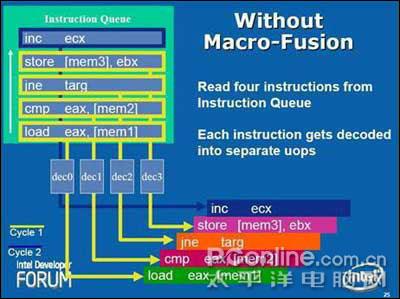
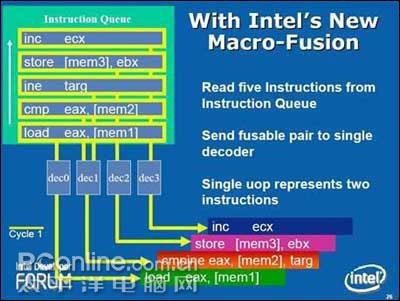
Core的内部线程 对于分支构架比P6宽的多的Core而言这样的旧式微指令处理能力是不够的,所以INTEL在Core中多加入了一组简单编译器(Simple Decoders),并且将MB微指令缓冲区的出口被扩宽至同时传送4条微指令。而更特别的是,过去需要堵塞着等待CD复杂编译器处理的许多内存和SSE数据现在可以由简单编译器来处理了,这都得宜于新的MIF微指令融合技术(Micro-ops Fusion)和改进的SSE,在下文中会详细介绍。 4、Core的指令融合技术 宏指令融合 Core前端处理环节新的突出能力是宏指令融合(Macro-Fusion),可以把多个X86指令融合在一起发送到到一个编译器转换为一个Uops微指令。多种指令将可以被融合,其中特别将compare和test指令融合到了分支指令(Branch Instructions)中。4个编译器都具有融合能力,但整个单元每周期只能完成一次宏指令融合。
Core的指令融合技术 除了在占用更少ROB和RS的情况下,宏指令融合(Macro-Fusion)还节约了内核前端的带宽,Core的解码单元能比过去快的多得清空IQ指令列队(Instruction Queue),而内核执行带宽也同样宽阔了很多,因为单个的ALU能同时执行2个X86指令,这些综合性能的提高使Core的实际处理效率比P6构架要提高多倍,远高于其可见的硬件单元增加幅度。
Core的指令融合技术 微指令融合 MIF微指令融合早先在Pentium M构架上就已经采用过,它和MF宏指令融合有着相似的功效,但是原理完全不一样。SD简单编译器(Simple/fast Decoder)把接收的单条X86指令转译为两条微指令,连接的两条微指令通过ROB发送到RS后,RS将把两条微指令分开来传输到不同的PORT中,平行的双通道同时传输,也可以是单通道的连续传输,这则取决于具体的处理情况。相对旧的MIF微指令融合技术,新的MIF支持了PORT的连续传输。 同宏指令融合技术相结合,Core构架在ROB和RS最大效率的流通更多的微指令、指令执行单元的处理速度和能力也极大提高的同时,反而占用了更少数量的硬件,这符合了Core高效率低功耗的设计原则。 [上一页] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] |
不支持Flash
| 新浪首页 > 科技时代 > 硬件 > 正文 |
|
|
|
| |||||||||||||||||||||||||||||||||||||



|
科技时代意见反馈留言板 电话:010-82628888-5595 欢迎批评指正 新浪简介 | About Sina | 广告服务 | 联系我们 | 招聘信息 | 网站律师 | SINA English | 会员注册 | 产品答疑 Copyright © 1996 - 2006 SINA Corporation, All Rights Reserved 新浪公司 版权所有 |