
ConroeгХЪЦЗжЮі Core vs K8МмЙЙНтЮі | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| http://www.sina.com.cn 2006Фъ05дТ09Ше 09:50 PCPOP-ЕчФдЪБЩа | ||||||||||
|
зїепЃКOCER.net ЁЁЁЁБрепзЂЃКЮхдТвЛШеЃЌОЭдкЮвУЧПЊЪМЯэЪмЮхвЛГЄМйЕФЪБКђЃЌAnandTech ЭјеОЗЂВМСЫетЦЊЙигк Intel Core ЮЂМмЙЙЕФЁЖIntel Core versus AMD's K8 architectureЁЗвЛЮФЁЃгыЮвУЧЯШЧАЗЂВМЕФЁЖIntel Core ЮЂМмЙЙШЋУцНтЮіЁЗвЛЮФЯрБШЃЌетЦЊЮФеТЙизЂЕФНЙЕуЪЧ Core ЮЂМмЙЙгы K8 ДІРэЦїЕФЖдБШЁЃВЂЧвЃЌИУЦЊЮФеТЕФзїепЪЧдкЗУЮЪЙ§ Intel вдЩЋСаЩшМЦЭХЖгЕФМмЙЙЩшМЦ ЁЁЁЁПэЖЏЬЌжДааЃЈWide Dynamic ExecutionЃЉЃЌИпМЖЪ§зжЖрУНЬхдіЧПММЪѕЃЈAdvanced Digital Media BoostЃЉЃЌжЧФмФкДцЗУЮЪММЪѕЃЈSmart Memory AccessЃЉЃЌИпМЖжЧФмЛКДцММЪѕЃЈAdvanced Smart CacheЃЉЁЊЁЊетаЉЖМЪЧ Intel ЕФЪаГЁВПШЫдБжиЕуаћДЋЕФММЪѕЃЌЫљгаЕФетаЉММЪѕдьОЭСЫ Intel аТЭЦГіЕФИпадФмЁЂЕЭЙІКФЕФ Core ЮЂМмЙЙЁЃ ЁЁЁЁВЛЙ§ЃЌЮвУЧВЛЛсжЛЙиаФЪаГЁаћДЋШЫдБИјЫћУЧЕФВњЦЗЬљЩЯЕФЦЏССЕФБъЧЉЁЃШчЙћжЛПДБъЧЉЕФЛАЁЊЁЊЁАНсКЯСМКУЕФадФмгыКЯРэЕФЙІКФЃЌРЉеЙЪ§зжЩњЛюЕФЗНЪНЁБЃЌФуЛсЗЂЯжетгы VIA ЖдЫћУЧЕФ C7 ДІРэЦїЕФаћДЋКмЯрЫЦЁЃШЛЖјЃЌФуШЯЮЊаћДЋПкКХБГКѓЕФ Intel Core ЮЂМмЙЙЛсгы VIA C7 ДІРэЦїЯрЭЌТ№ЃП ЁЁЁЁЯТУцЃЌОЭШУЮвУЧРДзаЯИСЫНтвЛЯТвўВидкЪаГЁаћДЋШЫдБЕФПкКХБГКѓЕФ Core ЮЂМмЙЙЕФУиУмЃЌВЂЧвгы AMD ЕФ K8 ЮЂМмЙЙЁЂIntel жЎЧАЕФ NetBurst ЮЂМмЙЙвдМА Pentium M ДІРэЦїНјааЖдБШЁЃзЋаДетЦЊЮФеТжЎЧАЃЌЮвУЧгы Intel вдЩЋСабаЗЂжааФЃЈIsrael Development CenterЃЌМђГЦIDCЃЉЕФМмЙЙЩшМЦЪІжЎвЛЁЊЁЊJack Doweck НјааСЫНЛСїЁЃJack Doweck ЩшМЦСЫШЋаТЕФФкДцТвађЛКГхЧјЃЈMemory Reorder BufferЃЉКЭФкДцЯрЙиаддЄВтЯЕЭГЃЈMemory disambiguation systemЃЉЁЃ ЁЁЁЁIntel ЕФЪаГЁаћДЋШЫдБЩљГЦ Core ЮЂМмЙЙЪЧ Pentium M ДІРэЦїКЭ NetBurst ЮЂМмЙЙЕФШкКЯЁЃШЛЖјФПЧАБШНЯЦеБщЕФПДЗЈЪЧЃЌCore ЮЂМмЙЙЪЧ Pentium Pro МмЙЙЃЌЛђепЫЕЪЧ P6 ЮЂМмЙЙЕФбгајЁЃдк Core ЮЂМмЙЙжаЃЌФуКмФбевЕНШЮКЮгыPentium 4ЃЌЛђепЫЕЪЧ NetBurst ЮЂМмЙЙгаЙиЕФЖЋЮїЁЃдкЮвУЧгы Jack Doweck ЕФНЛЬИжЎКѓЃЌетИіЪТЪЕИќМгЧхЮњЁЊЁЊCore ЮЂМмЙЙжажЛгадЄШЁЛњжЦЪЧДг NetBurst ЮЂМмЙЙЛёЕУЕФСщИаЃЌЫљгаЦфЫќЕФЩшМЦЖМЪЧДг Yonah ЮЂМмЙЙЃЈCore Duo ДІРэЦїЃЉбнБфЖјРДЃЌЖј Yonah ЮЂМмЙЙЯдШЛЪЧДг Banias ДІРэЦїКЭ Dothan ДІРэЦїбнБфЖјРДЕФЁЃЫљга BaniasЁЂDothanЁЂYonahКЭВЩгУ Core ЮЂМмЙЙЕФДІРэЦїЖММЬГаСЫ NetBurst ДІРэЦїЕФЧАЖЫзмЯпЩшМЦЃЌЕЋГ§ДЫжЎЭтЃЌЫќУЧКСЮовЩЮЪЖМЪЧдјОЛёЕУОоДѓГЩЙІЕФ P6 ЮЂМмЙЙЕФКѓДњЁЃдкФГжжвтвхЩЯЃЌФуПЩвдАб Core ЮЂМмЙЙНазіЁАP8 ЮЂМмЙЙЁБЃЌвђЮЊ Banias КЭ Dothan ДІРэЦїдјОБЛГЦзїЁАP7 ЮЂМмЙЙЁБЁЃЃЈВЛЙ§ЃЌашвЊзЂвтЕФЪЧЃЌIntel ДгЮДИјГіЙ§ Banias КЭ Dothan ДІРэЦїЫљВЩгУЕФЮЂМмЙЙЕФе§ЪНУћГЦЃЌЮвУЧвЛАугУ Pentium MДІРэЦїДњБэЫќУЧЃЌЛђепМђГЦЮЊ PM ДІРэЦїЁЃЃЉ ЁЁЁЁВЛЙ§етВЂВЛвтЮЖзХ Intel ЕФЙЄГЬЪІжЛЪЧАб Yonah ДІРэЦїЕФвЛаЉЙІФмЕЅдЊКЭНтТыЦїжиаТАќзАвЛЯТШЛКѓЛЛСЫИіУћзжОЭЭЦГіРДЁЃJack ИцЫпЮвУЧЃЌWoodcrestЁЂConroe КЭ Merom ДІРэЦїЖМЪЧЛљгк Yonah ДІРэЦїЕФЃЌЕЋЪЧМИКѕ80%ЕФМмЙЙКЭЕчТЗЩшМЦашвЊжиаТНјааЁЃ ЁЁЁЁЮЊЪЙФЧаЉВЛЪьЯЄДІРэЦїЩшМЦЕФЖСепвВФмРэНтЮФеТКѓУцЕФФкШнЃЌЮвУЧЪзЯШДгвЛИіДІРэЦїЮЂМмЙЙЕФЫйГЩНЬГЬПЊЪМЁЃЮЊСЫРэНтДІРэЦїЩшМЦЕФФПБъКЭгХСгЃЌФуЪзЯШашвЊСЫНтДІРэЦїжДааЕФжИСюЃЌЫљвдЮвУЧДгДІРэЦїдЫааЕФШэМўПЊЪМЁЃ ЁЁЁЁдкДІРэЦїЦЕТЪвбОДяЕН3GHzЩѕжСИќИпЕФЪБДњЃЌБЃжЄМДНЋгУЕНЕФжИСюКЭЪ§ОнвбОдкЛКДцжазМБИКУЪЧДІРэЦїЩшМЦепзюживЊЕФЙЄзїжЎвЛЁЃвђЮЊжЛгаетбљЃЌВХФмБЃжЄЫцзХДІРэЦїЦЕТЪЕФЬсИпадФмвВЫцжЎЬсИпЃЛЗёдђЕФЛАЃЌИќИпЕФДІРэЦїЦЕТЪжЛЛсЪЙДІРэЦїЛЈЗбИќЖрЕФЪБжгжмЦкРДЕШД§Ъ§ОнЁЃетжжАбЪ§ОнЬсЧАзАШыЛКДцЕФММЪѕБЛГЦЮЊЁАЪ§ОндЄШЁММЪѕЁБЃЈPrefechingЃЉЁЃЕЋЪЧЃЌжЎЧАЕФДІРэЦїВЩгУЕФЪ§ОндЄШЁММЪѕВЂВЛФмБЃжЄУПДЮЖМГЩЙІЃЌзмЛсгавЛаЉЪЇАмЕФЧщПіЁЃетЛсЕМжТДІРэЦїадФмНЕЕЭЃЌЬиБ№ЪЧдкдЫааЖдДјПэУєИаЕФгІгУГЬађЕФЪБКђЁЃ ЁЁЁЁCore ЮЂМмЙЙЫљВЩгУЕФЪ§ОндЄШЁММЪѕКСЮовЩЮЪЪЧФПЧАЮЊжЙзюЯШНјЕФЃЌвЊгХгк Pentium 4 КЭ Athlon 64 ЫљВЩгУЕФММЪѕЁЃCore ЮЂМмЙЙжаЕФУПИіКЫаФжСЩйга3зщдЄШЁЕЅдЊЃЌАќРЈ2зщЪ§ОндЄШЁЕЅдЊКЭ1зщжИСюдЄШЁЕЅдЊЁЃГ§ДЫжЎЭтЃЌЙВЯэЪНЖўМЖЛКДцЛЙгЕга2зщдЄШЁЕЅдЊЁЃетбљЃЌдквЛИіЫЋКЫаФЕФВЩгУ Core ЮЂМмЙЙЕФДІРэЦїжаЃЌЙВга8зщдЄШЁЕЅдЊЁЃгавЛИіЮЪЬтЪЧЃЌЖрДя8зщЕФдЄШЁЕЅдЊдкНјаадЄШЁЙЄзїЪБЃЌКмШнвзЛсЗСАЕНе§дкдЫааЕФГЬађЕФе§ГЃЕФ load ВйзїЁЃЮЊСЫБмУтетжжЧщПіЕФЗЂЩњЃЌCore ЮЂМмЙЙВЩШЁСЫдЄШЁМрВтЦїЕФЛњжЦЃЌИУМрВтЦїзмЛсИјгше§дкдЫааЕФГЬађИќИпЕФгХЯШМЖЁЃетбљЃЌдЄШЁЕЅдЊОЭОіВЛЛсДге§дкдЫааЕФГЬађФЧРяЁАЭЕЁБзпКмЖрДјПэСЫЁЃ ЁЁЁЁCore ЮЂМмЙЙЕФдЄШЁЛњжЦЛЙгаИќЖраТЬиадЁЃЪ§ОндЄШЁЕЅдЊОГЃашвЊдкЛКДцжаНјааБъЧЉВщевЁЃЮЊСЫБмУтв§Ц№е§дкдЫааЕФГЬађНјааЕФБъЧЉВщевЕФИќИпЕФбгГйЃЌЪ§ОндЄШЁЕЅдЊЪЙгУБъЧЉВщевЕФ store ЖЫПкЁЃШчЙћФуЛЙМЧЕУЃЌload ВйзїЕФЗЂЩњЦЕТЪЪЧ store ВйзїЕФ2БЖжЎЖрЃЌФЧУДОЭШнвзРэНтетбљЕФбЁдёСЫЁЊЁЊstore ЖЫПкЕФЪЙгУЦЕТЪНіЮЊ load ЖЫПкЕФвЛАыЁЃВЂЧвЃЌstore ВйзїдкДѓЖрЪ§ЧщПіЯТВЂВЛЪЧгАЯьЯЕЭГадФмЕФЙиМќЃЌвђЮЊдкЪ§ОнПЊЪМаДШыКѓЃЌДІРэЦїПЩвдТэЩЯПЊЪМНјааЯТУцЕФЙЄзїЃЌЖјВЛБиЕШД§аДШыВйзїЭъГЩЁЃЛКДц/ФкДцзгЯЕЭГЛсИКд№Ъ§ОнЕФећИіаДШыЕНЛКДцЁЂИДжЦЕНжїФкДцЕФЙ§ГЬЁЃ ЁЁЁЁCore ЮЂМмЙЙЕФЛКДцЯЕЭГвВСюШЫгЁЯѓЩюПЬЁЃЖўМЖЛКДцШнСПИпДя4MBЃЌВЂЧвЪЧгЩСНИіКЫаФЙВЯэЕФЃЌЗУЮЪбгГйНі12ЕН14ИіЪБжгжмЦкЁЃУПИіКЫаФЛЙгЕга32KBЕФвЛМЖжИСюЛКДцКЭвЛМЖЪ§ОнЛКДцЃЌЗУЮЪбгГйНіНі3ИіЪБжгжмЦкЁЃДг NetBurst ЮЂМмЙЙПЊЪМв§ШыЕФзЗзйЪНЛКДцЃЈTrace CacheЃЉдк Core ЮЂМмЙЙжаЯћЪЇСЫЁЃNetBurst ЮЂМмЙЙжаЕФзЗзйЪНЛКДцЕФзїгУгыГЃМћЕФжИСюЛКДцЯрРрЫЦЃЌЪЧгУРДДцЗХНтТыЧАЕФжИСюЕФЃЌЖд NetBurst ЮЂМмЙЙЕФГЄСїЫЎЯпНсЙЙЗЧГЃгагУЁЃЖј Core ЮЂМмЙЙЛиЙщЯрЖдНЯЖЬЕФСїЫЎЯпжЎКѓЃЌзЗзйЪНЛКДцвВЫцжЎЯћЪЇЃЌвђЮЊ Intel ШЯЮЊЃЌДЋЭГЕФвЛМЖжИСюЛКДцЖдЖЬСїЫЎЯпЕФ Core ЮЂМмЙЙИќМггагУЁЃ ЁЁЁЁЯТУцЕФБэИёВЛНіАќРЈСЫ Core ЮЂМмЙЙКЭ K8 ЮЂМмЙЙЕФДцДЂзгЯЕЭГЕФЬиадЃЌЛЙАќРЈСЫжЎЧАЕФ K7 ДІРэЦїЁЂPentium M ДІРэЦїМА Pentium 4 ДІРэЦїЕШЕФДцДЂзгЯЕЭГЕФЬиадЁЃ 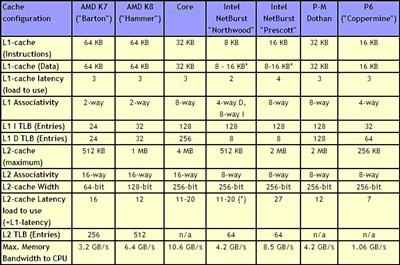 ЛКДцНсЙЙБШНЯ ЁЁЁЁЭЈЙ§фЏРРИУБэИёЃЌКмПьОЭПЩвдЗЂЯжЃЌCore ЮЂМмЙЙЕФДцДЂзгЯЕЭГИјШЫСєЯТЗЧГЃЩюПЬЕФгЁЯѓЁЃЫќВЛНігЕгазюДѓШнСПЕФЖўМЖЛКДцЃЌЖјЧвЛЙгЕгаНЯЕЭЕФЛКДцЗУЮЪбгГйЁЃЙВЯэЪНЖўМЖЛКДцЕФЩшМЦЛЙПЩвдЪЙЕЅИіКЫаФЯэгУЭъШЋЕФ4MBЛКДцЁЃвЛМЖЛКДцКЭЖўМЖЛКДцЕФзмЯпЮЛПэЖМЪЧ256-bitЃЌДгЖјПЩвдИјКЫаФЬсЙЉзюДѓЕФДцДЂДјПэЁЃ ЁЁЁЁCore ЮЂМмЙЙУцЖдЕФзюживЊЕФОКељЖдЪжЪЧ AMD ЕФ K8 ДІРэЦїЁЃДгБэИёжавВПЩвдПДГіЃЌK8 ДІРэЦїдкДцДЂзгЯЕЭГЩЯвВВЂЗЧШЋУцДІгкЯТЗчЃЌЖјЪЧгЕгаСНИіжЕЕУзЂвтЕФгХЪЦЁЃ ЁЁЁЁЪзЯШЪЧНЯДѓЕФвЛМЖЛКДцЃК64KBЕФвЛМЖжИСюЛКДцКЭ64KBЕФвЛМЖЪ§ОнЛКДцЁЃВЛЙ§ K8 ДІРэЦїЕФвЛМЖЛКДцВЩгУ2ТЗзщЯрСЌНсЙЙЁЃЯрБШжЎЯТЃЌCore ЮЂМмЙЙВЩгУЕФ8ТЗзщЯрСЌНсЙЙЕФ32KBЕФвЛМЖЛКДцВЂВЛЛсВюЖрЩйЁЃ ЁЁЁЁЕкЖўИігХЪЦЪЧИќМгживЊЕФвЛИіЃКK8 ДІРэЦїгЕгаМЏГЩдкДІРэЦїФкВПЕФФкДцПижЦЦїЁЃетбљЕФзіЗЈДѓДѓНЕЕЭСЫФкДцЗУЮЪбгГйЁЃВЛЙ§ЃЌВЩгУ Core ЮЂМмЙЙЕФДІРэЦїЕФИќПьЕФЧАЖЫзмЯпвВгааЇНЕЕЭСЫФкДцЗУЮЪбгГйЁЃОЭЮвУЧФПЧАЫљжЊЕРЕФЃЌK8 ДІРэЦїдкФкДцЗУЮЪбгГйЩЯЕФгХЪЦЛсЫѕЫЎЕННіНі15%~20%ЃЌЖјВЛЪЧгыPentium 4ЯрБШНЯЪБЕФМИКѕМгБЖЕФЫйЖШЃЈ45~50ФЩУыЖдБШ80~90ФЩУыЃЉЁЃ ЁЁЁЁМДБуШчДЫЃЌK8 ДІРэЦїЕФетСНЯюаЁаЁЕФгХЪЦвВгаПЩФмБЛгы Core ЮЂМмЙЙДцДЂзгЯЕЭГЦфЫћЗНУцЕФБШНЯЕжЯћЕєЁЃCore ЮЂМмЙЙЕФДІРэЦїБШОКељЖдЪж K8 ДІРэЦїгЕгаИќДѓЕФЖўМЖЛКДцКЭИќМгжЧФмЛЏЕФдЄШЁЛњжЦЁЃCore ЮЂМмЙЙЕФДІРэЦїЕФвЛМЖЛКДцгЕгаДѓдМ2БЖгк K8 ДІРэЦїЕФДјПэЃЈScienceMark ШэМўВтЪдЕФНсЙћЃЉЃЌЖјЦфЖўМЖЛКДцЕФЫйЖШИќЪЧ2.5БЖгк K8 ДІРэЦїЕФЖўМЖЛКДцЁЃ ЁЁЁЁгы K8 ДІРэЦїРрЫЦЃЌCore ЮЂМмЙЙЛсЖдШЁГіЕФжИСюНјаадЄНтТыЁЃдЄНтТыаХЯЂАќРЈжИСюГЄЖШКЭНтТыБпНчЁЃ ЁЁЁЁCore ЮЂМмЙЙзАБИСЫ4зщНтТыЕЅдЊЃЌетЪЧX86ДІРэЦїЪРНчЕФЕквЛДЮЁЃет4зщНтТыЕЅдЊАќРЈ3зщМђЕЅНтТыЕЅдЊКЭ1зщИДдгНтТыЕЅдЊЁЃЪЕМЪЩЯЃЌетжжАбМђЕЅжИСюгыИДдгжИСюЗжЖјжЮжЎЕФзіЗЈЃЌВЂЗЧЪЧ P6 ЮЂМмЙЙЕФзЈРћЁЃДгШЋЪРНчЕквЛИіСїЫЎЯпЛЏЕФX86ДІРэЦїЁЊЁЊ80486ПЊЪМЃЌЮЊСЫМгЫйМђЕЅжИСюЕФжДааЃЌетддђОЭвбОПЊЪМжїЕМЫљгаИпЫйX86ДІРэЦїЕФЮЂМмЙЙЁЃОЭЫуЪЧКХГЦЬсЙЉШ§зщЁАЭъећНтТыЕЅдЊЁБЕФ AMD K7ЁЂK8 ДІРэЦїЃЌЪЕМЪЩЯвВгаРрЫЦЕФЯожЦЁЃ ЁЁЁЁдкНщЩмЯТУцЕФФкШнжЎЧАЃЌЪзЯШШУЮвУЧНтЪЭвЛЯТЪВУДЪЧЮЂжИСюЃЈMicro-OpЃЉЁЃгЩгкX86жИСюМЏЕФжИСюГЄЖШЁЂИёЪНгыЖЈжЗФЃЪНЖМЯрЕБИДдгЃЌЮЊСЫМђЛЏЪ§ОнЭЈТЗЃЈData PathЃЉЕФЩшМЦЃЌДгКмОУвдЧАПЊЪМЃЌX86ДІРэЦїОЭВЩгУСЫНЋX86жИСюНтТыГЩ1ИіЛђЖрИіГЄЖШЯрЭЌЁЂИёЪНЙЬЖЈЁЂРрЫЦRISCжИСюаЮЪНЕФЮЂжИСюЕФЩшМЦЗНЗЈЃЌгШЦфЪЧЩцМАДцДЂЦїЗУЮЪЕФ load МА store жИСюЁЃЫљвдЃЌЯждкЕФX86ДІРэЦїЕФжДааЕЅдЊеце§жДааЕФжИСюЪЧНтТыКѓЕФЮЂжИСюЃЌЖјВЛЪЧX86жИСюЁЃ ЁЁЁЁЫљвдЃЌЖдX86ДІРэЦїРДЫЕЃЌНтТыЕЅдЊЕФШЮЮёВЛНіНіЪЧНтТыГіВйзїТыКЭВйзїЪ§ЕФЕижЗЃЌЛЙвЊАбГЄЖШДг1зжНкЕН15зжНкВЛЕШЕФX86жИСюзЊЛЏГЩШнвзЕїЖШКЭжДааЕФЙЬЖЈГЄЖШЕФРрЫЦRISCжИСюЕФЮЂжИСюЃЈMicro-OpЃЉЁЃ ЁЁЁЁГЃМћЕФЦеЭЈX86жИСюПЩвдгЩ3зщМђЕЅНтТыЕЅдЊжаЕФШЮКЮвЛзщЗвыГЩ1ЬѕЮЂжИСюЁЃСэЭт1зщИДдгНтТыЕЅдЊИКд№НтТывЛаЉИДдгЕФЁЂашвЊЗвыГЩ4ЬѕЮЂжИСюЕФX86жИСюЁЃЛЙгавЛаЉИќГЄЁЂИќИДдгЕФX86жИСюЃЌашвЊЮЂТыађСаЦїХфКЯИДдгНтТыЕЅдЊРДЗвыГЩЮЂжИСюЁЃетжжМђЕЅНтТыЕЅдЊгыИДдгНтТыЕЅдЊЯрХфКЯЕФНтТыЗНЪНБЛЯжДњЕФX86ДІРэЦїЫљЦеБщВЩгУЃЌАќРЈ P6 ЮЂМмЙЙЁЂK7 ДІРэЦїЁЂK8ДІРэЦїКЭ Pentium 4 ДІРэЦїЁЃ ЁЁЁЁCore ЮЂМмЙЙжаЕФНтТыЕЅдЊЛЙгЕгаИќЖраТЬиадЁЃЪзЯШЪЧКъжИСюШкКЯММЪѕЃЈMacro-Op FusionЃЉЁЃИУММЪѕПЩвдАб2ЬѕЯрЙиЕФX86жИСюШкКЯЮЊ1ЬѕЮЂжИСюЁЃР§ШчЃЌX86БШНЯжИСюcmpПЩвдгыЬјзЊжИСюjneШкКЯЁЃетРрЧщПівЛАуЗЂЩњдкГЬађжаЕФif-then-elseЗжжЇгяОфжаЁЃ 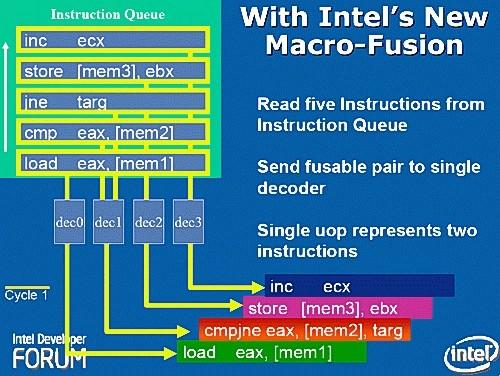 КъжИСюШкКЯММЪѕ
ЁЁЁЁКъжИСюШкКЯММЪѕДјРДЕФаЇЙћЪЧЗЧГЃУїЯдЕФЁЃдквЛИіДЋЭГЕФX86ГЬађжаЃЌУП10ЬѕжИСюОЭга2ЬѕжИСюПЩвдБЛШкКЯЁЃвВОЭЪЧЫЕЃЌКъжИСюШкКЯММЪѕЕФв§ШыПЩвдМѕЩй10%ЕФжИСюЪ§СПЁЃЖјЕБ2ЬѕX86жИСюБЛШкКЯЕФЪБКђЃЌ4зщНтТыЕЅдЊдкЕЅжмЦкФквЛЙВПЩвдНтТы5ЬѕX86жИСюЁЃБЛШкКЯЕФжИСюдкКѓУцЕФВйзїжаЭъШЋЪЧвЛИіећЬхЃЌетДјРДМИИігХЪЦЃКИќДѓЕФНтТыДјПэЃЌИќЩйЕФПеМфеМгУЃЌКЭИќЕЭЕФЕїЖШИКдиЁЃШчЙћ Intel аћГЦЕФЁАУП10ЬѕжИСюПЩвдШкКЯ1ДЮЁБЕФЫЕЗЈЪєЪЕЃЌФЧУДКъжИСюШкКЯММЪѕБОЩэОЭНЋДјРДОоДѓЕФадФмЬсЩ§ЁЃ ЁЁЁЁСэЭтвЛЯюММЪѕМДЮЂжИСюШкКЯММЪѕЃЌЪЧДгжЎЧАЕФ Pentium M ДІРэЦїМЬГаЖјРДЕФЁЃНщЩметЯюММЪѕжЎЧАЃЌЮвУЧЯШРДСЫНтвЛЯТЯрЙиЕФЮЪЬтКЭдчЦкЕФНтОіАьЗЈЁЃгавЛаЁВПЗжX86жИСюДІРэЦ№РДЗЧГЃРЇФбЃЌЕЋЪЧЭЌЪБгжЪЧЪЎЗжЕфаЭКЭГЃМћЕФX86жИСюЁЃвЛАуРДЫЕЃЌДцДЂЦїбАжЗЕФЫуЪѕВйзїОЭЪєгкетвЛРржИСюЃЌР§ШчЃЌADD [mem], EAXЁЃетБэЪОАбМФДцЦїEAXЕФФкШнгыЕижЗЮЊmemЕФФкДцЕЅдЊЕФФкШнЯрМгЃЌВЂАбМЦЫуНсЙћаДЛиИУФкДцЕЅдЊЁЃ ЁЁЁЁдкдчЦкЕФДІРэЦїЩшМЦжаЃЌАќРЈВЩгУ P6 ЮЂМмЙЙЕФPentium ProЁЂPentium II КЭ Pentium III ДІРэЦїЃЌШчЙћгіЕНетжжРраЭЕФжИСюЃЌФЧУДНтТыЕЅдЊНЋАбЫќНтТыГЩ2ЬѕЩѕжС3ЬѕЮЂжИСюЁЃМЧзЁЃЌДг P6 ЮЂМмЙЙжЎКѓЕФЯжДњX86ДІРэЦїЕФЩшМЦЫМЯыЪЧАбX86жИСюНтТыГЩРрЫЦRISCжИСюЕФЮЂжИСюЃЌШЛКѓдйАбетаЉЮЂжИСюЫЭЭљдНРДдНRISCЛЏЕФКѓЖЫЃЌЖјКѓЖЫвдРрЫЦRISCДІРэЦїЕФДІРэЗНЪННјааЕїЖШЁЂЗЂЩфЁЂжДааКЭЭЫГіЁЃ ЁЁЁЁЖдгкРрЫЦADD [mem], EAXетбљЕФжИСюЃЌФуУЛгаАьЗЈЫЭЭљRISCЛЏЕФжДааЕЅдЊЃЌвђЮЊЫќЮЅЗДСЫ RISC МмЙЙЕФИљБОЙцдђЁЊЁЊRISC МмЙЙЕФДІРэЦїЛсАбЫљгаЕФЪ§Он load ЕНМФДцЦїЃЌШЛКѓеыЖдМФДцЦїНјааВйзїЁЂМЦЫуЕШЁЃ ЁЁЁЁвђДЫЃЌADD [mem], EAXетЬѕжИСюЛсБЛНтТыГЩЖрЬѕЮЂжИСюЃЌМђЕЅЪОвтШчЯТЃК |

| аТРЫЪзвГ > ПЦММЪБДњ > гВМў > е§ЮФ |
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||



|
ПЦММЪБДњвтМћЗДРЁСєбдАхЁЁЕчЛАЃК010-82628888-5595ЁЁЁЁЁЁЛЖгХњЦРжИе§ аТРЫМђНщ | About Sina | ЙуИцЗўЮё | СЊЯЕЮвУЧ | еаЦИаХЯЂ | ЭјеОТЩЪІ | SINA English | ЛсдБзЂВс | ВњЦЗД№вЩ Copyright © 1996 - 2006 SINA Corporation, All Rights Reserved аТРЫЙЋЫОЁЁАцШЈЫљга |