
英特尔Core微架构全面解析(4) | |
|---|---|
| http://www.sina.com.cn 2006年04月27日 14:21 Ocer.net | |
|
Core 微架构前端的改进还包括分支预测单元。分支预测行为发生在取指单元部分。首先,它使用了很多人们已经熟知的预测单元,包括传统的 NetBurst 微架构上的分支目标缓冲区(Branch Target Buffer,简称BTB)、分支地址计算器(Branch Address Calculator,简称BAC)和返回地址栈(Return Address Stack,RAS)。然后,它还引入了2个新的预测单元――循环回路探测器(Loop Detector,简称LD)和间接分支预测器(Indirect Branch Predictor,简称IBP),其中循环回路探测器可以正确预测循环的结束,而间接分支预测器可以基于全局的历史信息做出预测。Core 微架构在分支预测方面不仅可以利用所有这些预测单元,还增加了新的特性:在之前的设计中,分支转移总是会浪费流水线的一个周期;Core 微架构在分支目标预测器和取指单元之间增加了一个队列,在大部分的情况下可以避免这一个周期的浪费。看起来很微不足道?要知道,对微内核设计来说,节省每一个可以节省的周期就是最大的目标;对已经发展了很多年的设计进行改进也是非常非常困难的。 Core 微架构的乱序执行引擎与 Yonah 微架构的设计类似,但是引入了更多的资源。如下图所示,Core 微架构与 Yonah 微架构在乱序执行引擎方面非常相似,包括寄存器别名表(Register Alias Table),分配器(Allocator)和乱序缓冲区(Reorder Buffer,简称ROB)。区别在于,所有的这些单元都被加大加宽,这样才可以配合更强劲的前端,容纳和调度更多的微指令,寻求更高的指令级并行度。 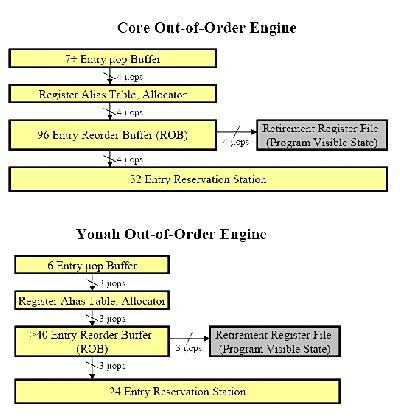 图9 Intel 三代微架构乱序执行引擎对比 NetBurst 微架构和 Yonah 微架构的最大吞吐量都是每周期3条微指令。相比之下,Core 微架构的最大吞吐量是每周期4条微指令。NetBurst 微架构的乱序缓冲区容量是126项,对 Yonah 微架构来说是多于40项,而 Core 微架构的乱序缓冲区容量是96项。 Intel 没有过多的透露关于乱序执行引擎的资料,但是对执行单元子系统的相关资料毫不吝啬,言之甚详。Core 微架构的执行单元部分拥有3个调度端口,通过这3个端口来调度执行单元。执行单元包括3个64bit的整数执行单元(ALU)、2个128bit的浮点执行单元(FPU)和3个128bit的SSE执行单元,或者更准确的说法应该是,向量执行单元或SIMD执行单元。其中,位于端口1的整数执行单元可以处理128bit的Shift和Rotate操作。而2个浮点单元和3个SSE单元共享某些硬件资源。NetBurst 微架构和 Yonah 微架构的执行单元子系统也在图中列出作为比较。 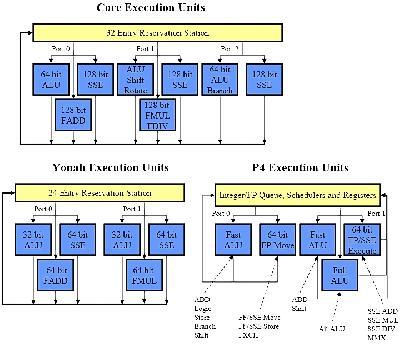 图10 Intel 三代微架构执行单元对比 很明显,我们首先注意到 Core 微架构拥有3个调度端口――比 NetBurst 微架构和 Yonah 微架构的2个端口增加了1个。所以,Core 微架构的执行单元子系统每个周期最多可以执行3条操作,而 Yonah 微架构最多只能执行2条。需要注意的是,对于 NetBurst 微架构来说,并不是2条。NetBurst 微架构的调度机制使得每个周期最多可以执行4条操作,但是这种情况会相当罕见――必须是4个简单的整数单元操作。并且,NetBurst 微架构在执行64bit指令时会有额外的延迟。更重要的是,Core 微架构的功能单元的统筹安排相对平衡,对于整数操作,可以在多个周期内保持单周期执行3个操作的吞吐量。而 NetBurst 微架构在很多情况下只能单周期执行1个操作。 Core 微架构有着数量众多的执行单元,形成了超乎寻常的处理资源。这庞大的执行单元不仅要求前端提供更多的微指令来喂饱自己,也对存储单元的处理能力提出了更高的要求。下图是 Core 微架构、Yonah 微架构和 NetBurst 微架构的存储单元对比,注意 NetBurst 微架构利用“fast ALU”来计算存储地址,因此并没有独立的存储地址单元。Core 微架构的存储系统源自 Yonah 微架构的设计,但是却拥有 NetBurst 微架构的超高带宽,实在是难能可贵。 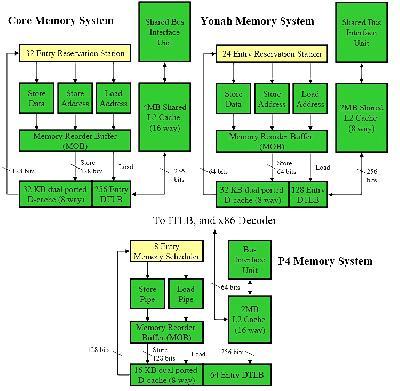 图11 Intel 三代微架构存储单元对比 Core 微架构和 Yonah 微架构的一级缓存与二级缓存都采用“写回”(Write Back)的存储方式,以64字节为存储单位。而对于 NetBurst 微架构来说,一级数据缓存采用“写直达”(Write Through)的存储方式,以64字节为存储单位;而二级缓存采用“写回”的存储方式,以128字节为存储单位。 |
| 新浪首页 > 科技时代 > 硬件 > 正文 |
|
|
|
| |||||||||||||||||||||||||||||||||||||



|
科技时代意见反馈留言板 电话:010-82628888-5595 欢迎批评指正 新浪简介 | About Sina | 广告服务 | 联系我们 | 招聘信息 | 网站律师 | SINA English | 会员注册 | 产品答疑 Copyright © 1996 - 2006 SINA Corporation, All Rights Reserved 新浪公司 版权所有 |