
AMD与奔腾4的终结!Intel世袭构架涅磐 | |
|---|---|
| http://www.sina.com.cn 2006年04月21日 12:21 太平洋电脑网 | |
|
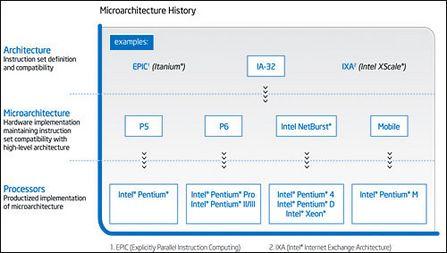
作者:刘凯821 一、Netburst终结 Core继承P6构架 2005年秋季的IDF上,INTEL正式宣布将采用全新构架的CPU来取代当前Netburst构架的Pentium 4系列,从笔记本使用的移动CPU到桌面CPU再到服务器的XEON系列,全部都将放弃现在的Netburst构架。Netburst在2001年5月登场取代P6构架的4年后,终于完成了它的历史使命,将燃烧的火炬交给了它的接班人。
刚刚结束的IDF揭开了新构架的神秘面纱,过去传言的构架名称“Merom”现在被INTEL纠正为正式发布的官方名称-“Core”,它将衍生为移动CPU版的Merom,桌面CPU的Conroe和服务器领域的Woodcrest。虽然INTEL声称Core是为适应新时代CPU在性能和功耗双方面的需要而全新设计的构架,但从官方发布的新构架技术文件来看,我倒认为Core其实是INTEL基于Pentium M(Banias)构架、溶入了Netburst精髓技术的改进构架。而Pentium M(Banias)本身就是由传统的P6构架改进而来(P6构架取代了Pentium的P5构架并沿用在PentiumPro、Pentium2、Pentium3上多年),所以Core构架的推广其实是P6家族的继承人重返了INTEL王座。
当INTEL的以色列团队宣称Core构架将沿用5年至10年时,他们的计划是在“多核”上发展,不过INTEL的多核概念和IBM及SUN的多核概念是不完全一样的,IBM及SUN的多核CPU目地是弥补单核CPU处理性能的不足,而INTEL的目的就多了一层意义-遵守摩尔定律预言的CPU发展道路,每2年将CPU的晶体管数量翻一倍。旧的Netburst构架的首要任务是提升运行频率,而新的Core构架的首要的任务则是更好的集成多颗核心、以更高的效率完成任务、保持高的功耗/性能比,集成更多的核心和缓存同时意味着集成更多的晶体管,而频率则因为流水线的数量少而提升的十分缓慢。不过按此发展势头,摩尔定律至少在近5年内是可以继续实现的,偏执狂INTEL的行动再次反驳了之前评论界盛行的摩尔定律失效论。
二、Core构架的思路与原则 在过几年里,大多数CPU都远离了乱序执行方式(OOOE)的内核设计思路,而偏向了有序执行(IOE),大量的VLIW处理器的性能都严重受限于程序与编码器,而现在Core的出现则代表了INTEL当前OOOE方式的最高设计水平,INTEL宣称Core将比现有的IOE处理器更好更合理的迅速处理完数据。
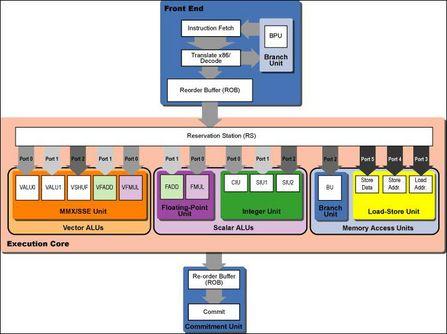
从Core的设计图我们可以看见,Core构架的每个环节都比过去的CPU更大更宽,它的向量和标量执行单元要比过去的Netburst构架大的多。更多更大似乎成为了Core设计组的核心思想-更大的DL解码逻辑电路、更大的RBS重排序缓存、更大的RS预留缓存、更大的数据输出口,更多的晶体管、更多的缓存,INTEL把一系列强大的硬件条件集合在了Core一体。 很明显,更宽的内部数据出口不一定就能带来大的性能提升,因为平行执行指令数量(ILP)的限制将导致多余的出口带宽处于空置状态,而另一方面缓存/内存的延迟也是整体处理速度严重滞后的因素之一。不过Core拥有一系列方法来解决ILP限制的问题,在数据前期处理方面有宏指令融合(Macro-Fusion)、微指令融合(Micro-ops Fusion)、分支预测单元(Branch Prediction Unit)等来保证编码快速送入到正确的执行单元,而在数据输出端则有主够的指令输出窗口(Instruction Window)来有序的分配每个流水线的任务,INTEL还特别提到他们已经改进了SSE指令中的一个重要缺陷,可以极大提高效率,以上这些多方面的全面改进使得Core的运算能力要比过去Netburst构架的CPU强大的多。 过去的P6构架最引人注目的就是它的数据出口结构(Issue Port),INTEL称之为分支端口(Dispatch Ports),而在现在最新的Core构架中也采用了相类似的设计,并针对Issue Port和Reservation Station做了大量的改进。
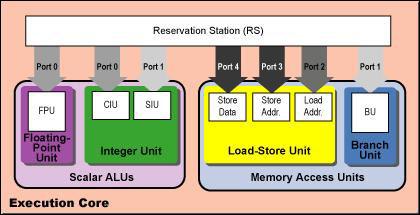
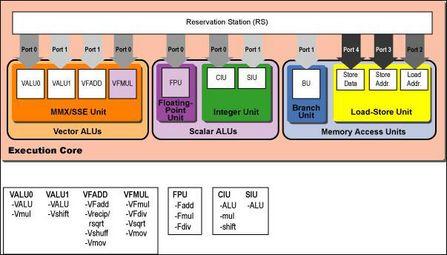
先来看看Pentium Pro的执行核心,PORT 0和PORT 1传输指令运算的硬件环节,而PORT 2、PORT 3、PORT 4连接着内存环节,这很容易发现老式的P6核心的预留缓存(Reservation Station)可以同时处理5周期指令,而这期间其执行核心(Execution Core)却只能处理1周期指令。 到了P6后续的改进版本,INTEL的Pentium 2和Pentium 3在执行核心(Execution Core)中加入了独立的整数运算(Integer Arithmetic)和向量浮点运算(Floating-Point Vector Arithmetic),占用的是PORT 0和PORT 1,这样0与1两个端口就变的十分拥挤了,下面为Pentium 3的最终改进版本结构图:
可以看见Pentium 3的数据分支线路也是很宽的,但是两大向量执行单元使用同一条出口端(Issue Bandwidth)的瓶颈使其能力大大受限。相对而言,后文将详细讲解的Core构架要强大的多,旧有的Pentium 3构架无论如何也不可能达到Core构架的内部数据处理/传输速度。
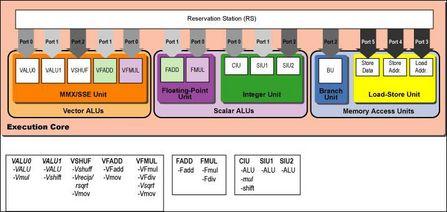
三、Core的整数与浮点执行核心 为配合Core增多的32条预留缓存空间(Reservation Station),Core的执行核心(Execution Core)也拥有了重新设计的数据输出端口(Issue Port) ,相比P6的5个端口及Netburst的4个端口,Core拥有了6个数据输出端口。其中3个端口专门负责指令执行单元,这将更好的满足现时CPU的巨大数据传输需要。
3.1、Core的整数执行单元 Integer execution units Core拥有3个64-bit整数执行单元(Integer Execution Units),每个单元可以独立处理一条64-bit整数数据,这样Core就有了一套64-bit的CIU复杂整数单元(Complex Integer Unit),这和P6构架相同。然后Core另外有2个SIU简单整数处理单元(Simple Integer Units)来快速运算较简单的任务,其中一个SIU将和分支执行单元BEU来共同完成部分的宏指令融合micro-ops fusion。上图中斜体字的部分尚未确定 对于INTEL的X86 CPU来说,这是首次可以在一周期内完成一阶64-bit的整数运算,这使Core已经走到了IBM PowerPC 970的前面-PowerPC 970需要有2个周期的延迟。另外,因为3个IEU整数执行核心使用了各自独立的PORT数据出口,所以整个Core处理器可以在一周期内同时执行3组64-bit的整数运算。 有着如此强大的整数处理单元,Core在性能上将比现有Pentium 4快的多,它在移动平台、服务器、3D图形上4倍于Pentium 4的性能表现将使全世界对INTEL CPU眼目一新。 3.2、Core的浮点执行单元 Floating-point execution units Core构架拥有2个浮点执行单元(Floating-Point Execution Units)同时处理向量和标量的浮点数据,位于PORT 1的FPEU-1浮点执行单元负责加减等简单的处理,而PORT 2的FPEU-2浮点执行单元则负责乘除等运算,这样在Core中就将FADD/VFADD和FMUL/VFMUL划分为两组,使其具备了在一周期中完成两条浮点指令的能力。
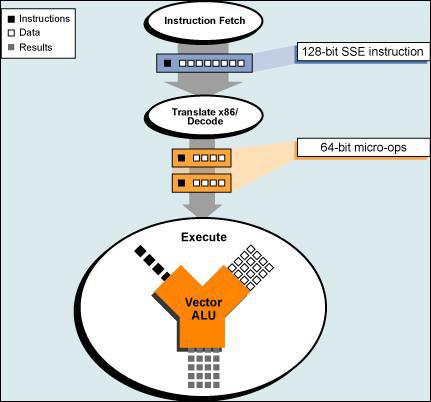
四、Core的向量执行单元 Apple的Fans可能会因为失去他们热爱的AltiVec而焦急,不过INTEL宣称Core将有极大的改进来执行面积向量数据,或称改进的SIMD。 浮点向量方面如前文所述,128-bit的FPEU浮点执行单元分为FADD/VFADD和FMUL/VFMUL两组,它们处理了全部的向量浮点数据,而FMUL/VFMUL线程还负责了向量平方根运算。 整数向量运算方面的改进版64-bit MMX和128-bit SSE目前还属于不能公开的CPU构架机密,不过位于PORT 0和PORT 1的向量整数单元(Vector Integer Units)扩宽至128-bit从而可以在一周期内完成一个128-bit的向量整数运算。可以肯定这个单元是和Pentium3中一样的结构,拥有一个128-bit VALU/shift单元和一个128-bit VALU/multiply单元。 另外在PORT 2还拥有第5条128-bit的向量处理流水线(Vector Pipeline) ,它负责寄存器内的向量寄存与移除,还要同时运行SSE转换、向量倒数与反平方根等任务,这个单元大体上就相当于PowerPC G4或者970上的AltiVec向量乱序单元。 以上是Core的向量单元硬件构架,接下来要介绍的是Core相对SSE/SSE2/SSE3最大的改进-真正的128-bit向量寻址单元。 4.1 真正128-bit的向量执行单元 True 128-bit vector processing 当INTEL最初兼容128-bit向量执行时,情况可能和编程人员及用户所预想不太一样,采用在P6和Banias构架上的SSE、SSE2和SSE3有2个重大的弱点,在ISA指令集架构方面,SSE最主要的缺点就是不支持3指令运算(Three-Operand),而支持Three-Operand的AltiVec则成为了当时更好的ISA。 P6构架的内部浮点处理和MMX都只有64-bit的带宽,所以进入SSE执行核心的只能是64-bit数据。为了让64-bit的SSE来处理128-bit指令,P6构架必须把128-bit的数据切割为2个64-bit的连续部分来处理。
这样折衷的处理方案使P6构架在处理128-bit数据时增加了一倍以上的延迟,而当时PowerPC G4的AltiVec只需要1个周期就能完成。同样不幸的是,Netburst的Pentium 4和Pentium M构架也都有这个弱点。
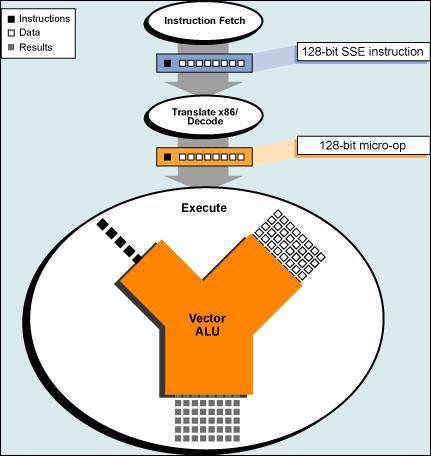
全新的Core终于拥有了一个周期完成128-bit向量运算的能力,INTEL终于把浮点和整数运算的内部带宽扩大到了128-bit,这不仅改进了延迟一周期的缺点,只有过去半数的微指令处理量也同样提高了解码、派址和带宽利用等多方面的速度。
这样全新构架的CPU将可以把128-bit的大量multiply/add/load/store/compare/jump等6套指令集成在一个周期中全部完成,其运用性能的飞跃幅度可想而知。
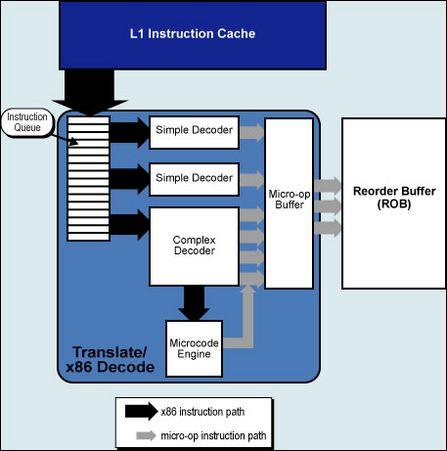
五、Core的内部线程 5.1、Core的流水线 INTEL还不能透露Core具体的流水线详情,目前我们只能告知Core采用14条流水线-这和 PowerPC 970是一样的,而之前的Pentium 4 Prescott拥有30条,P6构架为12条。短的流水线意味着Core在频率上的提升只能是缓慢的,而不能够像Pentium 4那样急速上升。 也可以这样猜想,其实Core的流水线设计和P6构架中的流水线是一模一样的,额外多出来的2条流水线完全是为了预留下CPU频率提升的空间而已。2条新的流水线各自成为Core流水线的入口和出口,成为了宏指令融合(Macro-Fusion)、微指令融合(Micro-Ops Fusion)等整合技术的输送站。
Core的ROB重排序缓冲区( Reorder Buffer)和RS预留缓存(Reservation Station)要比过去的Pentium M大了接近一倍,而事实上还必须考虑到新的宏指令融合(Macro-Fusion)、微指令融合(Micro-ops Fusion)等高效率的融合技术,这样以来,Core的内部转接速度至少要比Pentium M提高了3倍以上。 5.3、Core的处理前站-指令解码
这样的P6构架共有3个编译器每周期能执行6条Uops微指令,传送到MB微指令缓冲区,然后MB微指令缓冲区每次再传送3条微指令到ROB重排序缓冲区。
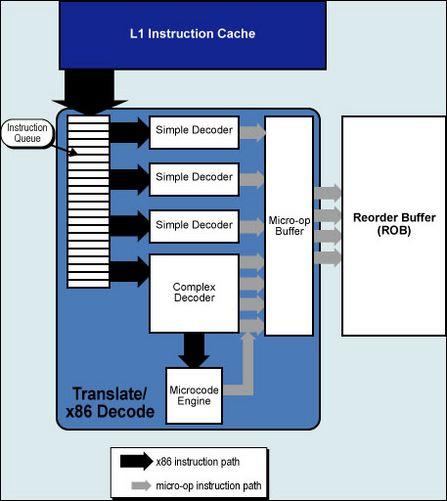
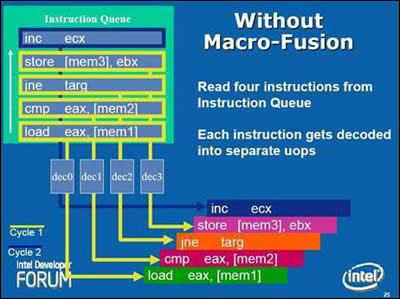
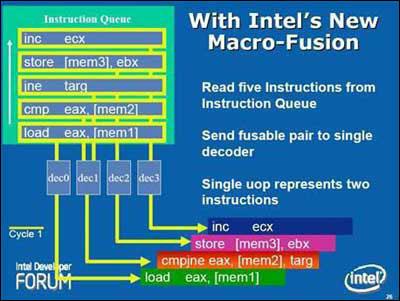
对于分支构架比P6宽的多的Core而言这样的旧式微指令处理能力是不够的,所以INTEL在Core中多加入了一组简单编译器(Simple Decoders),并且将MB微指令缓冲区的出口被扩宽至同时传送4条微指令。而更特别的是,过去需要堵塞着等待CD复杂编译器处理的许多内存和SSE数据现在可以由简单编译器来处理了,这都得宜于新的MIF微指令融合技术(Micro-ops Fusion)和改进的SSE,在下文中会详细介绍。 六、Core的指令融合技术 6.1、宏指令融合 Core前端处理环节新的突出能力是宏指令融合(Macro-Fusion),可以把多个X86指令融合在一起发送到到一个编译器转换为一个Uops微指令。多种指令将可以被融合,其中特别将compare和test指令融合到了分支指令(Branch Instructions)中。4个编译器都具有融合能力,但整个单元每周期只能完成一次宏指令融合。
除了在占用更少ROB和RS的情况下,宏指令融合(Macro-Fusion)还节约了内核前端的带宽,Core的解码单元能比过去快的多得清空IQ指令列队(Instruction Queue),而内核执行带宽也同样宽阔了很多,因为单个的ALU能同时执行2个X86指令,这些综合性能的提高使Core的实际处理效率比P6构架要提高多倍,远高于其可见的硬件单元增加幅度。
6.2、微指令融合 MIF微指令融合早先在Pentium M构架上就已经采用过,它和MF宏指令融合有着相似的功效,但是原理完全不一样。SD简单编译器(Simple/fast Decoder)把接收的单条X86指令转译为两条微指令,连接的两条微指令通过ROB发送到RS后,RS将把两条微指令分开来传输到不同的PORT中,平行的双通道同时传输,也可以是单通道的连续传输,这则取决于具体的处理情况。相对旧的MIF微指令融合技术,新的MIF支持了PORT的连续传输。 同宏指令融合技术相结合,Core构架在ROB和RS最大效率的流通更多的微指令、指令执行单元的处理速度和能力也极大提高的同时,反而占用了更少数量的硬件,这符合了Core高效率低功耗的设计原则。
七、Core的分支预测单元 在性能与能耗的平衡决策中,INTEL最终在Core的BP分支预测单元(Branch Predictor)上投入了大量的晶体管。 作为连接内存和CPU的重要环节,在BP分支预测上投入宝贵的晶体管资源是十分值得的。相对于预测错误后让CPU浪费时间和电耗来等待再次预测,一次准确的预测不仅仅节约了处理时间、提高了性能,也同样降低了CPU的功耗。 Core的三重分支预测单元实际上与Pentium M的预测单元是一样的,在Core的分支预测核心中存在一个双模态预测器和一个球型预测器,这些预测器记录下过去的执行历史并随时通知内核前端的ROB和RS,ROB和RS从BTB分支目标缓冲器(Branch Target Buffer)中快速取回所需要的数据地址,常规预测如通知一个分支在循环中仅在奇次迭代发生, 而不在偶次迭代中发生等, 这些在动态执行(P6系列)处理器上的静态预测技术还有有着长远的发展空间。
7.1、循环回路预测 分支历史表(Branch History Tables)不能够记录下足够详细的循环回路历史来准确预测下次的运算,所以每次循环回路的运行都浪费了大量的亢余时间。 循环回路预测(Loop Detector)则可以记录下每个循环回路结束前的所有的详细分支地址,当下一次同样的循环回路程序需要运算时,内核前端的ROB和RS就可以以100%的准确度来快速完成任务,Core构架拥有一个专门的运算法则来进行这种循环回路预测。 7.2、间接分支预测 间接分支预测(Indirect Branch Predictor)在运用时并不是立即分支,而是从寄存器中装载需要的预测目标,它实际上是一个首选目标地址的历史记录表。在ROB和RS需要间接分支的时候它就可以提供帮助,ROB和RS就可以快速提取到适用的结果,这与P6构架用可预测的条件分支替换间接分支来改善性能是相反的。 八、Core的存储器改进 乱序执行OOOE必须有序输出BIO的一个简单原因就是:存储器未确定其它操作全部结束前是不能轻易修改一个存储单元的。
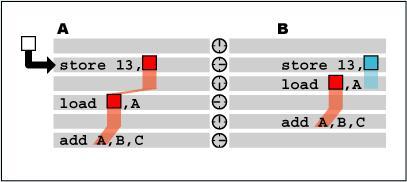
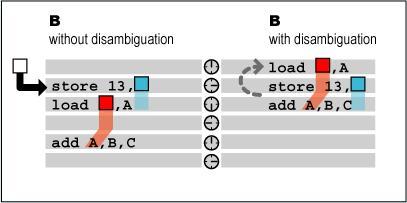
类似之前SIMD的8位、16位、 32位读写操作与MMX64位读写操作相混淆,及对同一存储区域先大数据量存贮然后小数据量读取或对同一存储区域先小数据量存贮再大数据量读取的情况,多种操作都可导致动态执行处理器的阻塞,虽然总体上只有3%的机率会出现存储混淆的错误,但过去的构架为预防存储混淆和堵塞采用了极其保守的方法-等待,这样就有大量的周期都浪费在存储器等待上。
在新的Core构架中,INTEL的设计师们使用了成熟的Memory Disambiguation技术,可以让存数和取数指令同时进行乱序执行而不用等待前排取数/存数指令的完成。这一优化使Core构架节约了大量的亢余周期,使其浮点存储器环节速度显著加快。
九、向着摩尔的指示前进 每两年将电路集成的晶体管数量翻倍,摩尔指示的这项艰巨任务需要INTEL数十年不懈的努力。在Netburst构架确定时,INTEL或许没有料想到90纳米时代的电子迁移问题会如此棘手,同样在未来分支预测的改进上也过于乐观,计划中轻松突破4G达到6G的梦想在高达120W的Pentium4功率现实中完全破灭-之前的IDF上,INTEL曾宣称能把频率为10G的CPU功耗控制在140W,这一切Netburst登场时的宏伟计划都在硅技术极限的限制上彻底失败,早在2004年就应该达到的4G目标直到现在也依然未完成。
Core构架放弃了超高频率的美好梦想,偏执狂INTEL面对高功耗低效能的Pentium4和AMD步步紧逼的Athlon64,反身转回了成熟稳健但频率提升不够迅速的P6构架,陧磐的Core构架至少要在未来的5年内承担起INTEL的梦想,从Core优良的单线程效率来看,它在目前所有X64构架CPU中是最优秀的,而它的多核设计也必将驱使整个软件业界快速向多核多线程发展。相信Hyperthreading也将很快融入Core构架足够宽大的内部结构中,多核整合Hyperthreading技术必将使Core构架发挥更强大的实力。 反观AMD近来停滞的K8构架,众多的评测结果都展示了Core构架较大的相对优势,或许AMD也是时候抓紧K10架构和anti-HT的改进了。 |
| ||||||||||||||||||||||||||||||||||||||||||
| 新浪首页 > 科技时代 > 硬件 > 正文 |
|

|
|
| ||||||||||||||||||||||||||||||||||||||||||||||


