
数据垄断和信息孤岛,是如何驯化我们的?
 本文共有6558字
本文共有6558字欢迎关注“创事记”的微信订阅号:sinachuangshiji
文/Lachel
来源:L先生说(ID:lxianshengmiao)
虽然看起来比较长
但我相信物有所值
最近,百度又挨骂了。
有文章称,百度搜索为自家产品(百家号)引流,致使搜索结果充斥着大量质量低劣的信息,已经沦为营销号的平台。
不少朋友问我怎么看,我有点诧异:
百度不是做贴吧、网盘和输入法的吗?怎么还有搜索功能?
好吧,开个玩笑。
不过说实话,近10年来我基本没有用过百度搜索。上一次打开,应该还是用来测网络连接。
不用的理由也很简单,主要倒不是因为广告,而是因为百度的内容实在太低劣了。
举个例子:就在写文章的此刻,我特地打开了百度搜索,搜了下“2018年GDP”。结果是,第一页9条结果(不算中间的各地新闻),只有2条能告诉我,统计局21日刚公布的18年中国GDP是多少。一不留神,很可能就错过了。
其他内容都是什么呢?超过一半是百家号的内容。
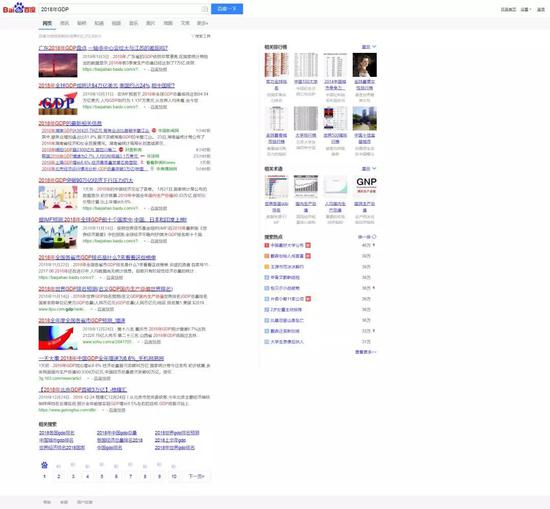
不是说百家号一定是营销号。但在这种场景下,作为一个普通用户,需要的是第一时间的触达,是权威媒体的一手信息,可靠的事实报道,严谨的数据呈现,而非自媒体们过时、没有门槛和信用背书的“评论”。
再举个例子。我随便在百度百科中搜索“斯坦福监狱实验”,看到的内容,是一篇没有数据、没有参考材料、没有任何学术性、充斥着大量可疑描写的东西。它的出处是什么呢?是一名豆瓣用户发的帖子……
至于对这个实验的各种引用和讨论,学界的相关研究,包括18年中撼动整个心理学界的“骗局”争议,以及菲利普·津巴多本人在知乎亲自撰写的回应,当然全都没有。
至于竞价排名、莆田系等问题,大家都已经熟知,就不说了。
很多人为百度开脱,说,一款产品,为自家的产品引流,有什么大不了的吗?其他公司不都一样?
但这正是最值得警惕的问题:
作为国内最大的搜索引擎,百度拥有实际上的信息垄断权力。
每天,可能有数以千万计的人从百度获取信息。这种垄断的权力,一旦被不当利用,跟利益挂钩,后果会有多可怕?
所以,我在以往的文章中,才一直呼吁:不要盲信百度。浪费时间精力倒是小事,更严重的后果是,它可能会降低你对信息的“品味”。
什么意思呢?长此以往,你可能会习惯低劣的信息。不再去要求严谨的论据,可靠的事实,精确的数据,中立的描写,严格的出处……习惯这些似是而非、片面简单的碎片内容。
这才是最可怕的。
但是如题目所言,这篇文章并不是为了骂百度。反正骂了也没有用,有用的东西又不能说。
我想和你聊的,是这背后折射延伸出来的一些问题。
众所周知,对于搜索引擎来讲,第一页的流量可能是第二页的数百倍,而在第一页里面,前几个链接的流量,又远远超过末尾的链接。
可以说,排序就是一切。
这已经成了衡量搜索引擎质量的一个指标。有一个段子是这样说的:把一样东西藏到哪里可以确保不会被人发现?谷歌搜索结果的第二页。
但是,越靠前的链接,就一定越好、越符合我们的需求吗?
在传统媒体中,决定版面位置的是编辑,这就是传播学里面的“把关人”效应 ——你所看到的一切东西,都是媒体编辑想让你看到的。
哪怕再公正、再客观的媒体,只要是“人”去操作,就存在“把关人”问题。
但把人换掉会更好吗?未必。
如果说搜索引擎排序的依据是算法,我们又凭什么去相信算法的完善、严谨,以及,相信算法背后的公司?
不说百度,就连谷歌,也遭受过许多质疑。
2016年美国大选期间,知名视频博主SourceFed就曾爆料,称谷歌屏蔽希拉里负面搜索建议。后来谷歌也作了回应,表示:当用户在谷歌搜索的时候,有关负面的建议词(像crime等词汇)会被自动降权,并无针对性。
但美国心理学家、PsychologyToday的前主编RobertEpstein做过实验后,认为:SourceFed的爆料大体是正确的,只是有点夸大。他认为,谷歌在对待希拉里和特朗普的搜索建议上,确实不太公平,对前者的负面屏蔽要比后者多。
RobertEpstein认为,如果此事属实,靠这个细微的区别,可能影响80-320万张选票。
2017年,欧盟反垄断委员会对谷歌罚款27亿美元,理由就是:谷歌涉嫌干预搜索结果,将用户引导向自己的服务,而将竞争对手的链接放到靠后的位置。这导致谷歌当年度收入受到重创。
2018年8月,美国中期选举前不久,媒体PJMedia发表了一篇文章,声称,在谷歌上搜索“特朗普新闻”相关关键词,排序靠前的结果中,有96%来自左翼媒体,占比最大的是和特朗普关系最差的CNN。
这当然有许多可能性——比如左翼媒体会更关注特朗普的过失,相对报道量更大,点击量也更高——但值得警惕的是:哪怕是地球上最好的搜索引擎,也会受到种种质疑和争论,更何况其他产品。
无论多么伟大的产品,一旦拥有了垄断的权力,结果都是可怕的。
没有任何一个媒体能像谷歌一样,能够干预数十亿人的信息接收,影响数十亿人的思维、认知,但问题是,又有谁来监督和约束谷歌?
同样,当百度垄断了你获取信息的渠道,当你习惯了不动脑子的吸收,你所看到的,就永远只是别人想让你看到的东西。
在你点开搜索引擎第一页的结果时,有没有想过:这些结果可能是受到干预的?有些东西可能是人为想让你看到,而有些东西,可能你永远看不到。
倘若首页超过50%的结果,被换成了自家的产品,那原本那些位置上放的是什么?它们又去了哪里?
如果盲信别人为你递上的结论,就相当于把思考和判断的权利,拱手让给了别人。
这只是一方面,另一方面,是互联网的开放性。
搜索引擎的本质驱动是什么?是互联网的开放性。可以说,如果没有开放性,搜索引擎的根基就会受损,从而也就没有了存在的理由。
但互联网真的是开放的吗?
如果把诞生于1995年的雅虎算作第一个搜索引擎,至今也有23年了。那时还是Web1.0时代,万维网刚具雏形。整个互联网就是一个平面的数据库,由各种彼此跳转的超链接文本组成。
一切信息都是开放的,可链接的,可触及的。而搜索引擎,就是这个数据库的目录。
但从Web2.0开始,事情发生了变化。
互联网厂商开始“圈地”,开始由平面向着立体进化,建筑起自己的一个个仓库。互联网的开放性被消解了,开始产生隐私、封闭性和信息壁垒。
为什么?很简单,因为大家开始意识到“数据”和“流量”的价值。
举个例子。我在公众号写过200篇文章,100多万字,但无论是用百度、必应还是谷歌(除了搜狗),都是几乎搜不到的,仿佛它们从未存在过。
同样,如果我想在这篇文章中,插入一些外部的链接,比如论文、网址,也是做不到的。我只能直接粘贴整个链接,再让读者手动选择、复制,跳转到浏览器里打开。
这就是微信公众号的封闭性。
不仅如此,微信对API把控得非常严。有一些抓取公众号文章,转化为RSS阅读的产品,出来后都会遭到针对性的封杀和升级应对,就是为了保障这种封闭性。
有了封闭性,数据就会被圈定在产品之中。你就必须每天都打开它,使用它,久而久之,习惯它,成为它的流量。
为什么所有的互联网产品都在推出App,都希望你去使用它们的移动应用?就是因为,使用App,你才能老老实实地“待”在里面,成为一名可量化、可跟踪的用户,而不是像网页一样,跳转、迁移、难以捉摸。
移动互联网有一个术语,叫做“激活成本”,指的就是获取一个有效用户的平均成本。这个指标从五六年前的几毛钱、几块钱,飙升到今天的几百块,仍然有无数公司在这片血海里厮杀,无非都是有利可图。
正是这些封闭的系统,把整个互联网,变成一个个的“信息孤岛”。
今天,我们手机里有各种各样的App。想知道附近有什么吃的,打开大众点评;想买东西,打开淘宝、京东、亚马逊;想看看大家都在关注什么,打开微博;无聊了,打开朋友圈……
但这些独立的App之间,信息能够互通吗?当然不能。
别说互通了,你的朋友圈能导出吗?你的微博能导出吗?你的淘宝搜索记录、浏览记录能导出吗?都不能。
甚至,根据微信的协议,我们的微信号并不属于我们,它是腾讯的资产,我们只有使用权。
我们产生了几乎无限的数据,根据这些数据,互联网厂商们可以精确地知道我们的爱好、习惯、行为,从而给我们推送精准的服务和广告。
而我们对这些数据,连基本的所有权都没有。
它们掌握在谁的手里呢?互联网巨头。为了从数据中攫取利益,巨头们营造出一个个信息孤岛,把信息进行割裂,树立壁垒,实现垄断,把我们“圈养”起来。
正如哥伦比亚大学法律系教授Tim Wu在《大变迁》一书中所说:通信技术的每一次主要变迁都遵循着相似的模式:最先出现的是短暂却足以让人感到兴奋的开放性阶段,随后带有垄断性质的封闭性阶段会逐渐取代前者。
Medium的创始人Ev Williams对此深有同感。他经常引述Tim Wu的观点:
“不论是铁路、电力、电报还是电话,这些事物最终都朝着封闭和垄断的阶段迈进。而且不论政府是否进行干预,在网络效应和规模经济效益的复合作用下,这个进程总会上演。”
互联网早已失去了开放性,它正在走向封闭。
在数据垄断和信息孤岛的分割下,互联网基本被割裂成了这几块:
• 信息海:完全开放的各类公开信息,也是唯一能被搜索引擎检索到的。
• 社交圈:微博、朋友圈、Twitter、Facebook等社交平台的信息。
• 垂直管:大众点评、美团、淘宝等生活所需的产品。
• 内容墙:视音频等多形态的内容产品,以及由付费制、会员制所隔绝出来的内容供应。
巨头们在做的事情,就是把各个“孤岛”聚合成“群岛”,并划分出自己的地盘,跟对手角力。
猜一猜,谷歌最大的竞争对手是谁?
不是百度,不是苹果,当然也不是亚马逊,而是Facebook。
原因很简单。这两家公司的主要营收都来自数字广告。根据谷歌和Facebook的2017年财报,两者的收入中,有80%来自广告业务。
另一个数据:按eMarketer的估算,2018年,谷歌的数字广告营收额将占整个美国市场的37.2%,Facebook预计将占19.6%,两者加起来瓜分了超过一半的市场份额。
这就导致了谷歌和Facebook之间势如水火的局势。如今,两者的全球用户早已超过10亿,每天产生难以计量的数据,但在谷歌上,你是找不到Facebook的任何内容的——因为Facebook不开放接口。
这就是“信息海”和“社交圈”之间的战争。谁能吸引更多的注意力,更多的用户时间,谁就能获得更多的数据,攫取更多的利益。
所以,为什么谷歌一直在做社交产品?就是为了分一杯羹。
并不只有Facebook在构建封闭的商业帝国,谷歌也是。
2012年,谷歌打造了自己的“知识图谱”项目。这个项目旨在为用户呈现更快、更有效的搜索结果,但与此同时,也让互联网变得更封闭。
什么意思呢?当你用谷歌搜索的时候,你可能会发现:有许多相关的信息,会直接以片段的形式,呈现在搜索结果页面上——你无须再去点击任何链接了。
比如,搜索一位名人,你会在右边看到他的简要信息、最新动向,以及一些相关问题。这些信息是怎么来的呢?通过“知识图谱”,从其他网站直接抓取来的。
这正是2005年谷歌CEOEricSchmidt所说的愿景:谷歌的理想图景,是让搜索结果直接回答用户的问题,不需要再点击链接。
本质上,这和Facebook是一样的:让数据和信息在内部流动,形成一个封闭的闭环。
他们正在不遗余力地“驯化”用户,让用户不再需要去行动和思考。
在这种情况下,自力更生,学会动手解决问题,就显得更加重要。
但可怕的是,我们也许已经习惯了被工具塑造,而遗忘了:我们才是工具的主体。我们使用工具,是为了更好地达成需求。
不久前,我做了个实验。我随机问了20位微信联系人。这里面,有不同年龄、不同工作的人,有关注了我公众号的,也有压根不知道我是谁的。
我问他们:你看订阅号时,会不会去点击右上角的菜单,从订阅号列表里去找你想看的号?
结果是什么呢?0。这20人中,没有一个人会主动去“搜寻”信息,全都习惯了被动刷信息流。
而这仅仅是多点一步操作而已。
这个实验当然不严谨,但可想而知,在日常生活中,当我们需要解决问题时,有多少人会具备“主动”意识——主动搜寻信息、整合信息、对比信息、反思信息,而非习惯了被信息所喂养。
我将获取信息的形式,分成三个层级。
第一个层级,是被动接受。不思考,不搜寻,不加工,遇到问题只会去询问别人,然后相信别人给你的内容。
第二个层级,是主动搜索。会通过不同渠道获取信息,但容易止步在“认知边界”之内,只相信自己已经相信的东西,只看到自己能看得到的东西。
第三个层级,是批判整合。在第二层级的基础上,会对信息内容进行批判审视,会跳出舒适区,找到对立面,会不断刷新自己的信息渠道和信息整合能力,从而获取更全面、更高层次的理解。
你处在的是哪一个层级?
很多人缺的,未必是搜索信息的能力,而是搜索信息的意识。我们习惯了相信别人,吸收别人告诉我们的结论,但却很少去反思、质问、对比、整合。
长此以往,我们会怎么样呢?被掌握了数据垄断和信息孤岛的巨头们所驯化。
他们用算法圈养我们,用兴趣吸引我们,用便利性让我们放弃对抗,用引导和喂养让我们放下思考。
慢慢的,我们会变成亿万数据当中,那一枚小小的碎片。
最后,提几个小建议。
我们难以改变外在环境,但可以不断去提升自我。比如:
1.提高搜索意识
即使前文提到过谷歌的种种争议,它仍然是全世界最好的搜索引擎。有条件用谷歌,没有条件用必应也行。
另外,学一些英语,在搜寻信息时,用中文和英文分别搜一下,对比一下,你可能会有更大的收获。
最重要的,是具备搜索信息的主动性。不要止步于最容易获得的内容,而是进一步思考:
• 这些信息是我要的吗?可靠吗?有效吗?
• 我还可以从哪里获取信息?
• 我还需要什么信息,来丰富、支撑和补充它们?
不仅仅局限于搜索引擎,也不仅局限于文本,书籍、音频、视频……这些都是信息的载体,都可能为你提供答案。
要有足够强的求知欲,不要满足于轻易能得到的信息,不妨多去深究和探索。
如同我在许多文章里强调过的:读书不要追求“读完”,它的本质是搜寻信息。
理解了这一点,你或许会有全然不同的视角。
2.建立自己的信息库
我有一个习惯:用谷歌搜索时,链到了一个网站,如果信息质量过关,我一定会把这个网站存下来,把它摸清楚,了解它的内容品味、倾向和类别。
然后,把它纳入我的信息库里面,需要时,直接去上面找。
这其中,有许多网站是注册制的,有些甚至是付费制——它们的绝大多数内容不会被谷歌所检索,你必须自己去挖掘和发现。
日积月累,这个庞大的信息库,就会成为可靠的信息来源。
如果你习惯了从门户网站、搜索引擎找信息,不妨先从践行这个习惯,落实信息库开始。
3.完善内在的知识体系
我在以前的文章中,多次提到过“反脆弱性”——即使绝大多数信息都可以从外部得到,我们也不能掉以轻心,完全把记忆、理解和思考交给它们。
为什么?原因很简单:我们能从外部得到的,永远只能是“信息”而非“知识”。
这些信息能构成什么结构,导出什么结论,采取什么态度,推出什么行动……这些,必须借由自己的知识体系进行加工才行。
你自身的知识体系越壮大,越完善,对外界信息的理解和吸收就会越全面、越高效。
那么,如何构建自己的知识体系呢?简单来说,就是三个步骤:
1)复述,用自己的话重构和提炼信息。
2)联系,把新信息跟旧信息联系起来,构成新的主题和框架。
3)更新,不断打破已有的结构,把新的节点纳入进来,使它更丰富和完善。
可以参考:建立知识体系,这份指南就够了
4.保持怀疑和审视
人永远无法克服大脑的缺陷,永远没有办法做到100%的理性、客观、中立。
那么,最好的办法,就是永远“留有余地”。
永远记住“我可能会犯错”,不断去问“有什么新的证据”,多去寻求对立面,打破自己的固有认知。
互联网会走向封闭,但我们的大脑可以保持开放。
没有什么是绝对正确的,如果有,那也只是怀疑本身。
(Lachel,25万关注的高效思维达人,知识管理专家,多家媒体专栏作家,36氪年度优秀作者。)

文章关键词: 网络文化


作者简介

L先生说
作者文章
推荐阅读
- 摩拜失去了灵魂,现在它又失去了姓名
-

- 走到最后,摩拜连姓名都不能拥有。详细>>
- 必须向抖音开放?微信没有这个义务
-

- 微信,作为一款社交软件工具,是否已经和“水电煤”一样,成为不可缺少的“基础设施”?又是否有义务,必须向抖音用户开放快捷登录?详细>>
- 影视资本自救指北:当演员“爆雷”之后
-

- 当影视资本遭遇演员人设“爆雷”后,他们又该如何自救?详细>>
- 重病患者百度
-

- 百度糟糕的财务表现,正在让它变得越来越短视。详细>>
新闻热榜



